SpikingFlow.softbp package¶
Subpackages¶
Submodules¶
SpikingFlow.softbp.accelerating module¶
-
SpikingFlow.softbp.accelerating.add(x: torch.Tensor, spike: torch.Tensor)[源代码]¶ - 参数
x – 任意tensor
spike – 脉冲tensor。要求spike中的元素只能为0或1,且spike.shape必须与x.shape相同
- 返回
x + spike
针对与脉冲这一特殊的数据类型,进行前反向传播加速并保持数值稳定的加法运算。
-
SpikingFlow.softbp.accelerating.sub(x: torch.Tensor, spike: torch.Tensor)[源代码]¶ - 参数
x – 任意tensor
spike – 脉冲tensor。要求spike中的元素只能为0或1,且spike.shape必须与x.shape相同
- 返回
x - spike
针对与脉冲这一特殊的数据类型,进行前反向传播加速并保持数值稳定的减法运算。
-
SpikingFlow.softbp.accelerating.mul(x: torch.Tensor, spike: torch.Tensor)[源代码]¶ - 参数
x – 任意tensor
spike – 脉冲tensor。要求spike中的元素只能为0或1,且spike.shape必须与x.shape相同
- 返回
x * spike
针对与脉冲这一特殊的数据类型,进行前反向传播加速并保持数值稳定的乘法运算。
-
class
SpikingFlow.softbp.accelerating.soft_vlotage_transform_function[源代码]¶ 基类:
torch.autograd.function.Function
-
SpikingFlow.softbp.accelerating.soft_vlotage_transform(v: torch.Tensor, spike: torch.Tensor, v_threshold: float)[源代码]¶ - 参数
v – 重置前电压
spike – 释放的脉冲
v_threshold – 阈值电压
- 返回
重置后的电压
根据释放的脉冲,以soft方式重置电压,即释放脉冲后,电压会减去阈值:\(v = v - s \cdot v_{threshold}\)。
该函数针对脉冲数据进行了前反向传播的加速,并能节省内存,且保持数值稳定。
SpikingFlow.softbp.functional module¶
-
SpikingFlow.softbp.functional.reset_net(net: torch.nn.modules.module.Module)[源代码]¶ - 参数
net – 任何属于nn.Module子类的网络
- 返回
None
将网络的状态重置。做法是遍历网络中的所有
Module,若含有reset()函数,则调用。
-
SpikingFlow.softbp.functional.spike_cluster(v: torch.Tensor, v_threshold, T_in: int)[源代码]¶ - 参数
v – shape=[T, N],N个神经元在t=[0, 1, …, T-1]时刻的电压值
v_threshold – 神经元的阈值电压,float或者是shape=[N]的tensor
T_in – 脉冲聚类的距离阈值。一个脉冲聚类满足,内部任意2个相邻脉冲的距离不大于T_in,而其内部任一脉冲与外部的脉冲距离大于T_in
- 返回
N_o: shape=[N],N个神经元的输出脉冲的脉冲聚类的数量
k_positive: shape=[N],bool类型的tensor,索引。需要注意的是,k_positive可能是一个全False的tensor
k_negative: shape=[N],bool类型的tensor,索引。需要注意的是,k_negative可能是一个全False的tensor
Gu P, Xiao R, Pan G, et al. STCA: Spatio-Temporal Credit Assignment with Delayed Feedback in Deep Spiking Neural Networks[C]. international joint conference on artificial intelligence, 2019: 1366-1372. 一文提出的脉冲聚类方法。如果想使用该文中定义的损失,可以参考如下代码:
v_k_negative = out_v * k_negative.float().sum(dim=0) v_k_positive = out_v * k_positive.float().sum(dim=0) loss0 = ((N_o > N_d).float() * (v_k_negative - 1.0)).sum() loss1 = ((N_o < N_d).float() * (1.0 - v_k_positive)).sum() loss = loss0 + loss1
-
SpikingFlow.softbp.functional.spike_similar_loss(spikes: torch.Tensor, labels: torch.Tensor, kernel_type='linear', loss_type='mse', *args)[源代码]¶ - 参数
spikes – shape=[N, M, T],N个数据生成的脉冲
labels – shape=[N, C],N个数据的标签,labels[i][k] == 1表示数据i属于第k类,labels[i][k] == 0则表示数据i不属于第k类,允许多标签
kernel_type – 使用内积来衡量两个脉冲之间的相似性,kernel_type是计算内积时,所使用的核函数种类
loss_type – 返回哪种损失,可以为’mse’, ‘l1’, ‘bce’
args – 用于计算内积的额外参数
- 返回
shape=[1]的tensor,相似损失
将N个数据输入到输出层有M个神经元的SNN,运行T步,得到shape=[N, M, T]的脉冲。这N个数据的标签为shape=[N, C]的labels。
用shape=[N, N]的矩阵sim表示相似矩阵,sim[i][j] == 1表示数据i与数据j相似,sim[i][j] == 0表示数据i与数据j不相似。若labels[i]与labels[j]共享至少同一个标签,则认为他们相似,否则不相似。
用shape=[N, N]的矩阵sim_p表示脉冲相似矩阵,sim_p[i][j]的取值为0到1,值越大表示数据i与数据j的脉冲越相似。
使用内积来衡量两个脉冲之间的相似性,kernel_type是计算内积时,所使用的核函数种类。
kernel_type == ‘linear’,线性内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \boldsymbol{x_{i}}^{T}\boldsymbol{y_{j}}\)。
kernel_type == ‘sigmoid’,sigmoid内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \mathrm{sigmoid}(\alpha \boldsymbol{x_{i}}^{T}\boldsymbol{y_{j}})\),其中 \(\alpha = args[0]\)。
kernel_type == ‘gaussian’,高斯内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \mathrm{exp}(- \frac{||\boldsymbol{x_{i}} - \boldsymbol{y_{j}}||^{2}}{2\sigma^{2}})\),其中 \(\sigma = args[0]\)。
当使用sigmoid或高斯内积时,内积的取值范围均在[0, 1]之间;而使用线性内积时,为了保证内积取值仍然在[0, 1]之间,会进行归一化:按照sim_p[i][j] = \(\frac{\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}})}{||\boldsymbol{x_{i}}|| · ||\boldsymbol{y_{j}}||}\)。
对于相似的数据,根据输入的loss_type,返回度量sim与sim_p差异的损失。
loss_type == ‘mse’时,返回sim与sim_p的均方误差(也就是l2误差)。
loss_type == ‘l1’时,返回sim与sim_p的l1误差。
loss_type == ‘bce’时,返回sim与sim_p的二值交叉熵误差。
注解
脉冲向量稀疏、离散,最好先使用高斯核进行平滑,然后再计算相似度。
-
SpikingFlow.softbp.functional.kernel_dot_product(x: torch.Tensor, y: torch.Tensor, kernel='linear', *args)[源代码]¶ - 参数
x – shape=[N, M]的tensor,看作是N个M维向量
y – shape=[N, M]的tensor,看作是N个M维向量
kernel – 计算内积时所使用的核函数
args – 用于计算内积的额外的参数
- 返回
ret, shape=[N. N]的tensor,ret[i][j]表示x[i]和y[j]的内积
计算批量数据x和y在核空间的内积。记2个M维tensor分别为 \(\boldsymbol{x_{i}}\) 和 \(\boldsymbol{y_{j}}\),则
kernel == ‘linear’,线性内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \boldsymbol{x_{i}}^{T}\boldsymbol{y_{j}}\)。
kernel == ‘polynomial’,多项式内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = (\boldsymbol{x_{i}}^{T}\boldsymbol{y_{j}})^{d}\),其中 \(d = args[0]\)。
kernel == ‘sigmoid’,sigmoid内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \mathrm{sigmoid}(\alpha \boldsymbol{x_{i}}^{T}\boldsymbol{y_{j}})\),其中 \(\alpha = args[0]\)。
kernel == ‘gaussian’,高斯内积,\(\kappa(\boldsymbol{x_{i}}, \boldsymbol{y_{j}}) = \mathrm{exp}(- \frac{||\boldsymbol{x_{i}} - \boldsymbol{y_{j}}||^{2}}{2\sigma^{2}})\),其中 \(\sigma = args[0]\)。
-
SpikingFlow.softbp.functional.set_threshold_margin(output_layer: SpikingFlow.softbp.neuron.BaseNode, label_one_hot: torch.Tensor, eval_threshold=1.0, threshold0=0.9, threshold1=1.1)[源代码]¶ - 参数
output_layer – 用于分类的网络的输出层,输出层输出shape=[batch_size, C]
label_one_hot – one hot格式的样本标签,shape=[batch_size, C]
eval_threshold – 输出层神经元在测试(推理)时使用的电压阈值
threshold0 – 输出层神经元在训练时,负样本的电压阈值
threshold1 – 输出层神经元在训练时,正样本的电压阈值
- 返回
None
对于用来分类的网络,为输出层神经元的电压阈值设置一定的裕量,以获得更好的分类性能。
类别总数为C,网络的输出层共有C个神经元。网络在训练时,当输入真实类别为i的数据,输出层中第i个神经元的电压阈值会被设置成threshold1,而其他神经元的电压阈值会被设置成threshold0。而在测试(推理)时,输出层中神经元的电压阈值被统一设置成eval_threshold。
-
SpikingFlow.softbp.functional.redundant_one_hot(labels: torch.Tensor, num_classes: int, n: int)[源代码]¶ - 参数
labels – shape=[batch_size]的tensor,表示batch_size个标签
num_classes – int,类别总数
n – 表示每个类别所用的编码数量
- 返回
shape=[batch_size, num_classes * n]的tensor
对数据进行冗余的one hot编码,每一类用n个1和(num_classes - 1) * n个0来编码。
示例:
>>> num_classes = 3 >>> n = 2 >>> labels = torch.randint(0, num_classes, [4]) >>> labels tensor([0, 1, 1, 0]) >>> codes = functional.redundant_one_hot(labels, num_classes, n) >>> codes tensor([[1., 1., 0., 0., 0., 0.], [0., 0., 1., 1., 0., 0.], [0., 0., 1., 1., 0., 0.], [1., 1., 0., 0., 0., 0.]])
-
SpikingFlow.softbp.functional.first_spike_index(spikes: torch.Tensor)[源代码]¶ - 参数
spikes – shape=[*, T],表示任意个神经元在t=0, 1, …, T-1,共T个时刻的输出脉冲
- 返回
index, shape=[*, T],为True的位置表示该神经元首次释放脉冲的时刻
输入任意个神经元的输出脉冲,返回一个与输入相同shape的bool类型的index。index为True的位置,表示该神经元首次释放脉冲的时刻。
示例:
>>> spikes = (torch.rand(size=[2, 3, 8]) >= 0.8).float() >>> spikes tensor([[[0., 0., 0., 0., 0., 0., 0., 0.], [1., 0., 0., 0., 0., 0., 1., 0.], [0., 1., 0., 0., 0., 1., 0., 1.]], [[0., 0., 1., 1., 0., 0., 0., 1.], [1., 1., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0.]]]) >>> first_spike_index(spikes) tensor([[[False, False, False, False, False, False, False, False], [ True, False, False, False, False, False, False, False], [False, True, False, False, False, False, False, False]], [[False, False, True, False, False, False, False, False], [ True, False, False, False, False, False, False, False], [False, False, False, True, False, False, False, False]]])
SpikingFlow.softbp.layer module¶
-
class
SpikingFlow.softbp.layer.NeuNorm(in_channels, k=0.9)[源代码]¶ 基类:
torch.nn.modules.module.Module警告
可能是错误的实现。测试的结果表明,增加NeuNorm后的收敛速度和正确率反而下降了。
- 参数
in_channels – 输入数据的通道数
k – 动量项系数
Wu Y, Deng L, Li G, et al. Direct Training for Spiking Neural Networks: Faster, Larger, Better[C]. national conference on artificial intelligence, 2019, 33(01): 1311-1318. 中提出的NeuNorm层。NeuNorm层必须放在二维卷积层后的脉冲神经元后,例如:
Conv2d -> LIF -> NeuNorm
要求输入的尺寸是[batch_size, in_channels, W, H]。
in_channels是输入到NeuNorm层的通道数,也就是论文中的 \(F\)。
k是动量项系数,相当于论文中的 \(k_{\tau 2}\)。
论文中的 \(\frac{v}{F}\) 会根据 \(k_{\tau 2} + vF = 1\) 自动算出。
-
forward(in_spikes: torch.Tensor)[源代码]¶ - 参数
in_spikes – 来自上一个卷积层的输出脉冲,shape=[batch_size, in_channels, W, H]
- 返回
正则化后的脉冲,shape=[batch_size, in_channels, W, H]
-
training: bool¶
-
class
SpikingFlow.softbp.layer.DCT(kernel_size)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
kernel_size – 进行分块DCT变换的块大小
将输入的shape=[*, W, H]的数据进行分块DCT变换的层,*表示任意额外添加的维度。变换只在最后2维进行,要求W和H都能整除kernel_size。
DCT是AXAT的一种特例。
-
training: bool¶
-
class
SpikingFlow.softbp.layer.AXAT(in_features, out_features)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
in_features – 输入数据的最后2维的尺寸
out_features – 输出数据的最后2维的尺寸
对输入数据 \(X\) 进行线性变换 \(AXA^{T}\) 的操作。
要求输入数据的shape=[*, in_features, in_features],*表示任意额外添加的维度。
将输入的数据看作是批量个shape=[in_features, in_features]的矩阵,而 \(A\) 是shape=[out_features, in_features]的矩阵。
-
training: bool¶
-
class
SpikingFlow.softbp.layer.Dropout(p=0.5)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
p – 设置为0的概率
与torch.nn.Dropout的操作相同,但是在每一轮的仿真中,被设置成0的位置不会发生改变;直到下一轮运行,即网络调用reset()函数后,才会按照概率去重新决定,哪些位置被置0。
torch.nn.Dropout在SNN中使用时,由于SNN需要运行一定的步长,每一步运行(t=0,1,…,T-1)时都会有不同的dropout,导致网络的结构实际上是在持续变化:例如可能出现t=0时刻,i到j的连接被断开,但t=1时刻,i到j的连接又被保持。
在SNN中的dropout应该是,当前这一轮的运行中,t=0时若i到j的连接被断开,则之后t=1,2,…,T-1时刻,i到j的连接应该一直被断开;而到了下一轮运行时,重新按照概率去决定i到j的连接是否断开,因此重写了适用于SNN的Dropout。
小技巧
从之前的实验结果可以看出,当使用LIF神经元,损失函数或分类结果被设置成时间上累计输出的值,torch.nn.Dropout几乎对SNN没有影响,即便dropout的概率被设置成高达0.9。可能是LIF神经元的积分行为,对某一个时刻输入的缺失并不敏感。
-
training: bool¶
-
class
SpikingFlow.softbp.layer.Dropout2d(p=0.2)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
p – 设置为0的概率
与torch.nn.Dropout2d的操作相同,但是在每一轮的仿真中,被设置成0的位置不会发生改变;直到下一轮运行,即网络调用reset()函数后,才会按照概率去重新决定,哪些位置被置0。
-
forward(x: torch.Tensor)[源代码]¶ - 参数
x – shape=[N, C, W, H]的tensor
- 返回
shape=[N, C, W, H],与x.shape相同的tensor
-
training: bool¶
-
class
SpikingFlow.softbp.layer.LowPassSynapse(tau=100.0, learnable=False)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
tau – 突触上电流衰减的时间常数
learnable – 时间常数是否设置成可以学习的参数。当设置为可学习参数时,函数参数中的tau是该参数的初始值
具有低通滤波性质的突触。突触的输出电流满足,当没有脉冲输入时,输出电流指数衰减:
\[\tau \frac{\mathrm{d} I(t)}{\mathrm{d} t} = - I(t)\]当有新脉冲输入时,输出电流自增1:
\[I(t) = I(t) + 1\]记输入脉冲为 \(S(t)\),则离散化后,统一的电流更新方程为:
\[I(t) = I(t-1) - (1 - S(t)) \frac{1}{\tau} I(t-1) + S(t)\]这种突触能将输入脉冲进行“平滑”,简单的示例代码和输出结果:
T = 50 in_spikes = (torch.rand(size=[T]) >= 0.95).float() lp_syn = LowPassSynapse(tau=10.0) pyplot.subplot(2, 1, 1) pyplot.bar(torch.arange(0, T).tolist(), in_spikes, label='in spike') pyplot.xlabel('t') pyplot.ylabel('spike') pyplot.legend() out_i = [] for i in range(T): out_i.append(lp_syn(in_spikes[i])) pyplot.subplot(2, 1, 2) pyplot.plot(out_i, label='out i') pyplot.xlabel('t') pyplot.ylabel('i') pyplot.legend() pyplot.show()
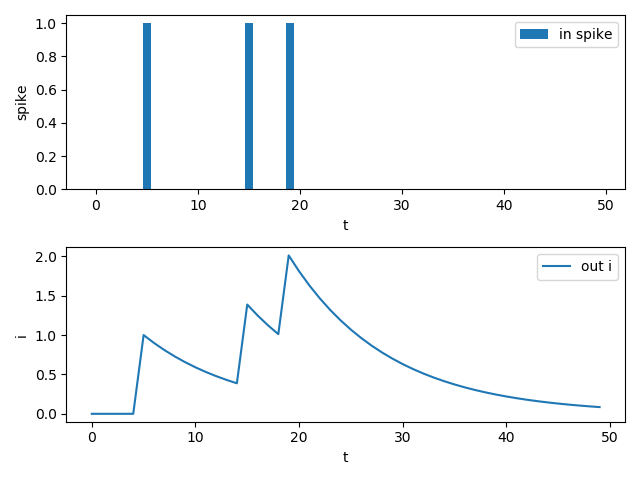
输出电流不仅取决于当前时刻的输入,还取决于之前的输入,使得该突触具有了一定的记忆能力。
这种突触偶有使用,例如:
Diehl P U, Cook M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity.[J]. Frontiers in Computational Neuroscience, 2015: 99-99.
Fang H, Shrestha A, Zhao Z, et al. Exploiting Neuron and Synapse Filter Dynamics in Spatial Temporal Learning of Deep Spiking Neural Network[J]. arXiv: Neural and Evolutionary Computing, 2020.
另一种视角是将其视为一种输入为脉冲,并输出其电压的LIF神经元。并且该神经元的发放阈值为 \(+\infty\) 。
神经元最后累计的电压值一定程度上反映了该神经元在整个仿真过程中接收脉冲的数量,从而替代了传统的直接对输出脉冲计数(即发放频率)来表示神经元活跃程度的方法。因此通常用于最后一层,在以下文章中使用:
Lee C, Sarwar S S, Panda P, et al. Enabling spike-based backpropagation for training deep neural network architectures[J]. Frontiers in Neuroscience, 2020, 14.
-
training: bool¶
SpikingFlow.softbp.neuron module¶
-
class
SpikingFlow.softbp.neuron.BaseNode(v_threshold=1.0, v_reset=0.0, pulse_soft=Sigmoid(), monitor_state=False)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
v_threshold – 神经元的阈值电压
v_reset – 神经元的重置电压。如果不为None,当神经元释放脉冲后,电压会被重置为v_reset;如果设置为None,则电压会被减去阈值
pulse_soft – 反向传播时用来计算脉冲函数梯度的替代函数,即软脉冲函数
monitor_state – 是否设置监视器来保存神经元的电压和释放的脉冲。 若为True,则self.monitor是一个字典,键包括’v’和’s’,分别记录电压和输出脉冲。对应的值是一个链表。为了节省显存(内存),列表中存入的是原始变量 转换为numpy数组后的值。还需要注意,self.reset()函数会清空这些链表
softbp包中,可微分SNN神经元的基类神经元。
可微分SNN神经元,在前向传播时输出真正的脉冲(离散的0和1)。脉冲的产生过程可以看作是一个阶跃函数:
\[ \begin{align}\begin{aligned}S = \Theta(V - V_{threshold})\\\begin{split}其中\Theta(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \end{cases}\end{split}\end{aligned}\end{align} \]\(\Theta(x)\) 是一个不可微的函数,用一个形状与其相似的函数 \(\sigma(x)\),即代码中的pulse_soft去近似它的梯度。默认的pulse_soft = SpikingFlow.softbp.soft_pulse_function.Sigmoid(),在反向传播时用 \(\sigma'(x)\) 来近似 \(\Theta'(x)\),这样就可以使用梯度下降法来更新SNN了。
前向传播使用 \(\Theta(x)\),反向传播时按前向传播为 \(\sigma(x)\) 来计算梯度,在PyTorch中很容易实现,参见这个类的spiking()函数。
-
set_monitor(monitor_state=True)[源代码]¶ - 参数
monitor_state – True或False,表示开启或关闭monitor
- 返回
None
设置开启或关闭monitor。
-
training: bool¶
-
class
SpikingFlow.softbp.neuron.IFNode(v_threshold=1.0, v_reset=0.0, pulse_soft=Sigmoid(), monitor_state=False)[源代码]¶ 基类:
SpikingFlow.softbp.neuron.BaseNode- 参数
v_threshold – 神经元的阈值电压
v_reset – 神经元的重置电压
pulse_soft – 反向传播时用来计算脉冲函数梯度的替代函数,即软脉冲函数
monitor_state – 是否设置监视器来保存神经元的电压和释放的脉冲。 若为True,则self.monitor是一个字典,键包括’v’和’s’,分别记录电压和输出脉冲。对应的值是一个链表。为了节省显存(内存),列表中存入的是原始变量 转换为numpy数组后的值。还需要注意,self.reset()函数会清空这些链表
IF神经元模型,可以看作理想积分器,无输入时电压保持恒定,不会像LIF神经元那样衰减:
\[\frac{\mathrm{d}V(t)}{\mathrm{d} t} = R_{m}I(t)\]电压一旦达到阈值v_threshold则放出脉冲,同时电压归位到重置电压v_reset。
-
training: bool¶
-
class
SpikingFlow.softbp.neuron.LIFNode(tau=100.0, v_threshold=1.0, v_reset=0.0, pulse_soft=Sigmoid(), monitor_state=False)[源代码]¶ 基类:
SpikingFlow.softbp.neuron.BaseNode- 参数
tau – 膜电位时间常数,越大则充电越慢
v_threshold – 神经元的阈值电压
v_reset – 神经元的重置电压
pulse_soft – 反向传播时用来计算脉冲函数梯度的替代函数,即软脉冲函数
monitor_state – 是否设置监视器来保存神经元的电压和释放的脉冲。 若为True,则self.monitor是一个字典,键包括’v’和’s’,分别记录电压和输出脉冲。对应的值是一个链表。为了节省显存(内存),列表中存入的是原始变量 转换为numpy数组后的值。还需要注意,self.reset()函数会清空这些链表
LIF神经元模型,可以看作是带漏电的积分器:
\[\tau_{m} \frac{\mathrm{d}V(t)}{\mathrm{d}t} = -(V(t) - V_{reset}) + R_{m}I(t)\]电压在不为v_reset时,会指数衰减。
-
training: bool¶
-
class
SpikingFlow.softbp.neuron.PLIFNode(init_tau=2.0, v_threshold=1.0, v_reset=0.0, pulse_soft=Sigmoid(), monitor_state=False)[源代码]¶ 基类:
SpikingFlow.softbp.neuron.BaseNode- 参数
init_tau – 初始的tau
v_threshold – 神经元的阈值电压
v_reset – 神经元的重置电压
pulse_soft – 反向传播时用来计算脉冲函数梯度的替代函数,即软脉冲函数
monitor – 是否设置监视器来保存神经元的电压和释放的脉冲。 若为True,则self.monitor是一个字典,键包括’v’和’s’,分别记录电压和输出脉冲。对应的值是一个链表。为了节省显存(内存),列表中存入的是原始变量 转换为numpy数组后的值。还需要注意,self.reset()函数会清空这些链表
Parametric LIF神经元模型,时间常数tau可学习的LIF神经元:
\[\tau_{m} \frac{\mathrm{d}V(t)}{\mathrm{d}t} = -(V(t) - V_{reset}) + R_{m}I(t)\]电压在不为v_reset时,会指数衰减。对于同一层神经元,它们的tau是共享的。
小技巧
LIF神经元的电压更新方程为:
self.v += (dv - (self.v - self.v_reset)) / self.tau为了防止出现除以0的情况,PLIF神经元没有使用除法,而是用乘法代替:
self.v += (dv - (self.v - self.v_reset)) * self.tau-
training: bool¶
-
class
SpikingFlow.softbp.neuron.RIFNode(init_w=- 0.001, amplitude=None, v_threshold=1.0, v_reset=0.0, pulse_soft=Sigmoid(), monitor_state=False)[源代码]¶ 基类:
SpikingFlow.softbp.neuron.BaseNode- 参数
init_w – 初始的自连接权重
amplitude – 对自连接权重的限制。若为
None,则不会对权重有任何限制; 若为一个float,会限制权重在(- amplitude, amplitude)范围内; 若为一个tuple,会限制权重在(amplitude[0], amplitude[1])范围内。v_threshold – 神经元的阈值电压
v_reset – 神经元的重置电压
pulse_soft – 反向传播时用来计算脉冲函数梯度的替代函数,即软脉冲函数
monitor_state – 是否设置监视器来保存神经元的电压和释放的脉冲。 若为True,则self.monitor是一个字典,键包括’v’和’s’,分别记录电压和输出脉冲。对应的值是一个链表。为了节省显存(内存),列表中存入的是原始变量 转换为numpy数组后的值。还需要注意,self.reset()函数会清空这些链表
Recurrent IF神经元模型。与Parametric LIF神经元模型类似,但有微妙的区别,自连接权重不会作用于输入。其膜电位更新方程为:
\[\frac{\mathrm{d}V(t)}{\mathrm{d}t} = w(V(t) - V_{reset}) + R_{m}I(t)\]其中 \(w\) 是自连接权重,权重是可以学习的。对于同一层神经元,它们的 \(w\) 是共享的。
-
training: bool¶
SpikingFlow.softbp.optim module¶
-
class
SpikingFlow.softbp.optim.AdamRewiring(params, lr=0.001, betas=0.9, 0.999, eps=1e-08, weight_decay=0, amsgrad=False, T=1e-05, l1=1e-05)[源代码]¶ 基类:
torch.optim.optimizer.Optimizer注意
该算法的收敛性尚未得到任何证明,以及在基于softbp的SNN上的剪枝可靠性也未知。
- 参数
params – (原始Adam)网络参数的迭代器,或者由字典定义的参数组
lr – (原始Adam)学习率
betas – (原始Adam)用于计算运行时梯度平均值的以及平均值平方的两个参数
eps – (原始Adam)除法计算时,加入到分母中的小常数,用于提高数值稳定性
weight_decay – (原始Adam)L2范数惩罚因子
amsgrad – (原始Adam)是否使用AMSGrad算法
T – Deep R算法中的温度参数
l1 – Deep R算法中的L1惩罚参数
Bellec et al, “Deep Rewiring: Training very sparse deep networks,” ICLR 2018.
该实现将论文中的基于SGD优化算法的 Deep R 算法移植到 Adam: A Method for Stochastic Optimization 优化算法上,是基于Adam算法在Pytorch中的 官方实现 修改而来。
SpikingFlow.softbp.soft_pulse_function module¶
-
class
SpikingFlow.softbp.soft_pulse_function.bilinear_leaky_relu[源代码]¶ 基类:
torch.autograd.function.Function
-
class
SpikingFlow.softbp.soft_pulse_function.BilinearLeakyReLU(a=1, b=0.01, c=0.5)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
a – -c <= x <= c 时反向传播的梯度
b – x > c 或 x < -c 时反向传播的梯度
c – 决定梯度区间的参数
- 返回
与输入相同shape的输出
双线性的近似脉冲发放函数。梯度为
\[\begin{split}g'(x) = \begin{cases} a, & -c \leq x \leq c \\ b, & x < -c ~or~ x > c \end{cases}\end{split}\]对应的原函数为
\[\begin{split}g(x) = \begin{cases} bx + bc - ac, & x < -c \\ ax, & -c \leq x \leq c \\ bx - bc + ac, & x > c \\ \end{cases}\end{split}\]-
training: bool¶
-
class
SpikingFlow.softbp.soft_pulse_function.Sigmoid(alpha=1.0)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
x – 输入数据
alpha – 控制反向传播时梯度的平滑程度的参数
- 返回
与输入相同shape的输出
反向传播时使用sigmoid的梯度的脉冲发放函数。反向传播为
\[g'(x) = \alpha * (1 - \mathrm{sigmoid} (\alpha x)) \mathrm{sigmoid} (\alpha x)\]对应的原函数为
\[g(x) = \mathrm{sigmoid}(\alpha x) = \frac{1}{1+e^{-\alpha x}}\]-
training: bool¶
-
class
SpikingFlow.softbp.soft_pulse_function.SignSwish(beta=5.0)[源代码]¶ 基类:
torch.nn.modules.module.Module- 参数
x – 输入数据
beta – 控制反向传播的参数
- 返回
与输入相同shape的输出
Darabi, Sajad, et al. “BNN+: Improved binary network training.” arXiv preprint arXiv:1812.11800 (2018).
反向传播时使用swish的梯度的脉冲发放函数。反向传播为
\[g'(x) = \frac{\beta (2 - \beta x \mathrm{tanh} \frac{\beta x}{2})}{1 + \mathrm{cosh}(\beta x)}\]对应的原函数为
\[g(x) = 2 * \mathrm{sigmoid}(\beta x) * (1 + \beta x (1 - \mathrm{sigmoid}(\beta x))) - 1\]-
training: bool¶
Module contents¶
-
class
SpikingFlow.softbp.ModelPipeline[源代码]¶ 基类:
torch.nn.modules.module.Module用于解决显存不足的模型流水线。将一个模型分散到各个GPU上,流水线式的进行训练。设计思路与仿真器非常类似。
运行时建议先取一个很小的batch_size,然后观察各个GPU的显存占用,并调整每个module_list中包含的模型比例。
-
append(nn_module, gpu_id)[源代码]¶ - 参数
nn_module – 新添加的module
gpu_id – 该模型所在的GPU,不需要带“cuda:”的前缀。例如“2”
- 返回
None
将nn_module添加到流水线中,nn_module会运行在设备gpu_id上。添加的nn_module会按照它们的添加顺序运行。例如首先添加了 fc1,又添加了fc2,则实际运行是按照input_data->fc1->fc2->output_data的顺序运行。
-
constant_forward(x, T, reduce=True)[源代码]¶ - 参数
x – 输入数据
T – 运行时长
reduce – 为True则返回运行T个时长,得到T个输出的和;为False则返回这T个输出
- 返回
T个输出的和或T个输出
让本模型以恒定输入x运行T次,这常见于使用频率编码的SNN。这种方式比forward(x, split_sizes)的运行速度要快很多
-
forward(x, split_sizes)[源代码]¶ - 参数
x – 输入数据
split_sizes – 输入数据x会在维度0上被拆分成每split_size一组,得到[x0, x1, …],这些数据会被串行的送入 module_list中的各个模块进行计算
- 返回
输出数据
例如将模型分成4部分,因而
module_list中有4个子模型;将输入分割为3部分,则每次调用forward(x, split_sizes),函数内部的 计算过程如下:step=0 x0, x1, x2 |m0| |m1| |m2| |m3| step=1 x0, x1 |m0| x2 |m1| |m2| |m3| step=2 x0 |m0| x1 |m1| x2 |m2| |m3| step=3 |m0| x0 |m1| x1 |m2| x2 |m3| step=4 |m0| |m1| x0 |m2| x1 |m3| x2 step=5 |m0| |m1| |m2| x0 |m3| x1, x2 step=6 |m0| |m1| |m2| |m3| x0, x1, x2
不使用流水线,则任何时刻只有一个GPU在运行,而其他GPU则在等待这个GPU的数据;而使用流水线,例如上面计算过程中的
step=3到step=4,尽管在代码的写法为顺序执行:x0 = m1(x0) x1 = m2(x1) x2 = m3(x2)
但由于PyTorch优秀的特性,上面的3行代码实际上是并行执行的,因为这3个在CUDA上的计算使用各自的数据,互不影响
-
training: bool¶
-