分类DVS128 Gesture¶
本教程作者: fangwei123456
在上一个教程 神经形态数据集处理 中,我们预处理了DVS128 Gesture数据集。接下来,我们将搭建SNN 对DVS128 Gesture数据集进行分类,我们将使用 Incorporating Learnable Membrane Time Constant to Enhance Learning of Spiking Neural Networks 1 一文中的网络,其中神经元使用LIF神经元,池化选用最大池化。
原文 1 使用老版本的惊蜇框架,原始代码和训练日志可以在此处获取: Parametric-Leaky-Integrate-and-Fire-Spiking-Neuron
在本教程中,我们使用新版的惊蛰框架,将拥有更快的训练速度。
定义网路¶
原文 1 使用下图所示的通用结构表示用于各个数据集的网络。
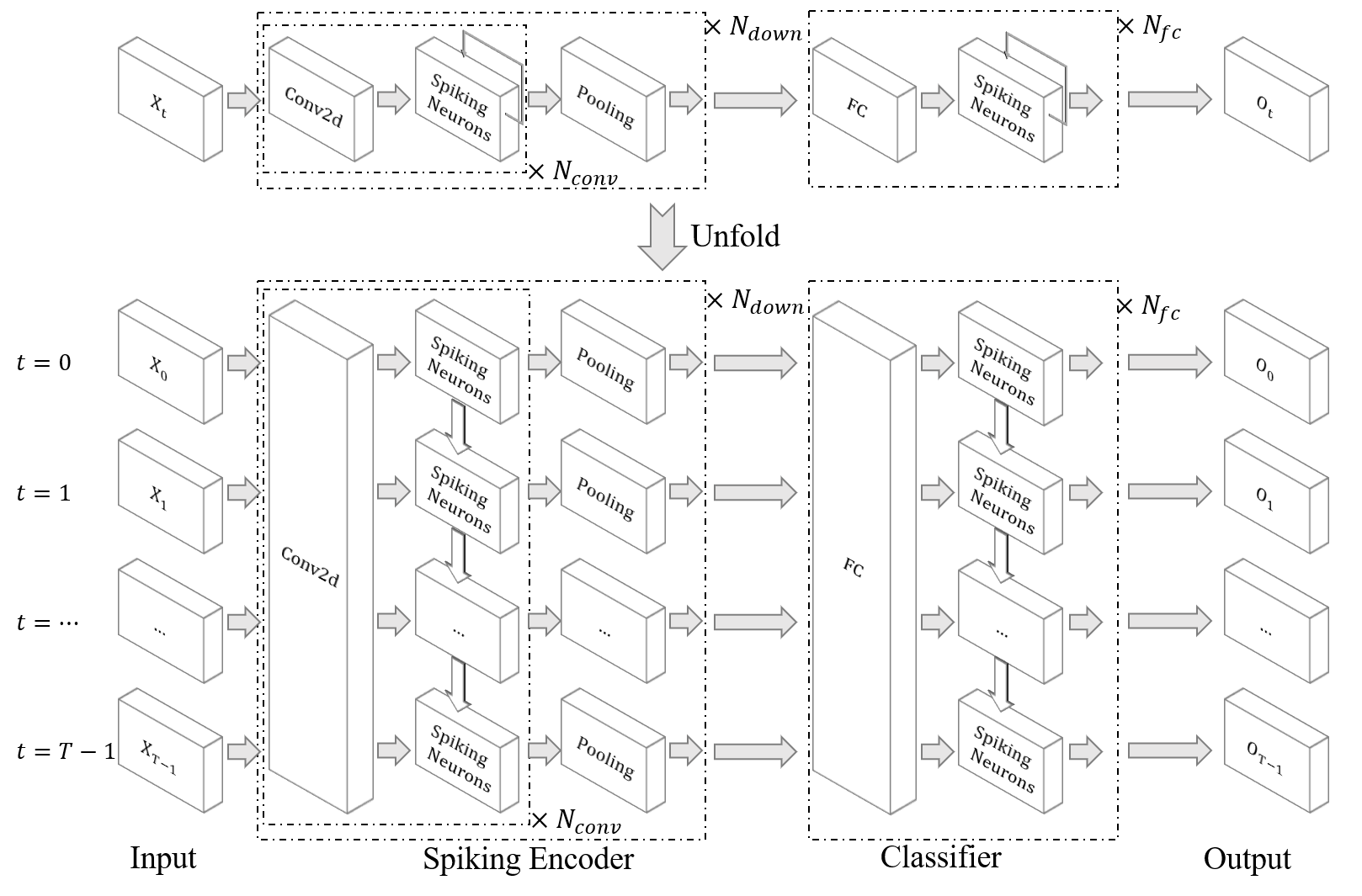
对于DVS128 Gesture数据集,\(N_{conv}=1, N_{down}=5, N_{fc}=2\)。
具体的的网路结构为 {c128k3s1-BN-LIF-MPk2s2}*5-DP-FC512-LIF-DP-FC110-LIF-APk10s10},其中 APk10s10 是额外增加的投票层。
符号的含义如下:
c128k3s1:
torch.nn.Conv2d(in_channels, out_channels=128, kernel_size=3, padding=1)BN:
torch.nn.BatchNorm2d(128)MPk2s2:
torch.nn.MaxPool2d(2, 2)DP:
spikingjelly.clock_driven.layer.Dropout(0.5)FC512:
torch.nn.Linear(in_features, out_features=512APk10s10:
torch.nn.AvgPool1d(2, 2)
简单起见,我们使用逐步仿真的方式定义网络,代码实现如下:
class VotingLayer(nn.Module):
def __init__(self, voter_num: int):
super().__init__()
self.voting = nn.AvgPool1d(voter_num, voter_num)
def forward(self, x: torch.Tensor):
# x.shape = [N, voter_num * C]
# ret.shape = [N, C]
return self.voting(x.unsqueeze(1)).squeeze(1)
class PythonNet(nn.Module):
def __init__(self, channels: int):
super().__init__()
conv = []
conv.extend(PythonNet.conv3x3(2, channels))
conv.append(nn.MaxPool2d(2, 2))
for i in range(4):
conv.extend(PythonNet.conv3x3(channels, channels))
conv.append(nn.MaxPool2d(2, 2))
self.conv = nn.Sequential(*conv)
self.fc = nn.Sequential(
nn.Flatten(),
layer.Dropout(0.5),
nn.Linear(channels * 4 * 4, channels * 2 * 2, bias=False),
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True),
layer.Dropout(0.5),
nn.Linear(channels * 2 * 2, 110, bias=False),
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True)
)
self.vote = VotingLayer(10)
@staticmethod
def conv3x3(in_channels: int, out_channels):
return [
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
neuron.LIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True)
]
定义前向传播和损失¶
设置仿真时长为 T,batch size为 N,则从 DataLoader 中获取的数据 x.shape=[N, T, 2, 128, 128]。我们定义的网络是按照逐
步仿真的方式,最好先将 x 进行转换,转换为 shape=[T, N, 2, 128, 128]。
将 x[t] 送入网络,累加输出脉冲,除以总仿真时长,最终得到了脉冲发放频率 out_spikes / x.shape[0],它是一个 shape=[N, 11] 的tensor。
def forward(self, x: torch.Tensor):
x = x.permute(1, 0, 2, 3, 4) # [N, T, 2, H, W] -> [T, N, 2, H, W]
out_spikes = self.vote(self.fc(self.conv(x[0])))
for t in range(1, x.shape[0]):
out_spikes += self.vote(self.fc(self.conv(x[t])))
return out_spikes / x.shape[0]
损失定义为脉冲发放频率和ont hot形式标签的MSE:
for frame, label in train_data_loader:
optimizer.zero_grad()
frame = frame.float().to(args.device)
label = label.to(args.device)
label_onehot = F.one_hot(label, 11).float()
out_fr = net(frame)
loss = F.mse_loss(out_fr, label_onehot)
loss.backward()
optimizer.step()
functional.reset_net(net)
使用CUDA神经元和逐层传播¶
如果读者对惊蜇框架的传播模式不熟悉,建议先阅读之前的教程: 传播模式 和 使用CUDA增强的神经元与逐层传播进行加速。
逐步传播的代码通俗易懂,但速度较慢,现在让我们将原始网络改写为逐层传播:
import cupy
class CextNet(nn.Module):
def __init__(self, channels: int):
super().__init__()
conv = []
conv.extend(CextNet.conv3x3(2, channels))
conv.append(layer.SeqToANNContainer(nn.MaxPool2d(2, 2)))
for i in range(4):
conv.extend(CextNet.conv3x3(channels, channels))
conv.append(layer.SeqToANNContainer(nn.MaxPool2d(2, 2)))
self.conv = nn.Sequential(*conv)
self.fc = nn.Sequential(
nn.Flatten(2),
layer.MultiStepDropout(0.5),
layer.SeqToANNContainer(nn.Linear(channels * 4 * 4, channels * 2 * 2, bias=False)),
neuron.MultiStepLIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True, backend='cupy'),
layer.MultiStepDropout(0.5),
layer.SeqToANNContainer(nn.Linear(channels * 2 * 2, 110, bias=False)),
neuron.MultiStepLIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True, backend='cupy')
)
self.vote = VotingLayer(10)
def forward(self, x: torch.Tensor):
x = x.permute(1, 0, 2, 3, 4) # [N, T, 2, H, W] -> [T, N, 2, H, W]
out_spikes = self.fc(self.conv(x)) # shape = [T, N, 110]
return self.vote(out_spikes.mean(0))
@staticmethod
def conv3x3(in_channels: int, out_channels):
return [
layer.SeqToANNContainer(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
),
neuron.MultiStepLIFNode(tau=2.0, surrogate_function=surrogate.ATan(), detach_reset=True, backend='cupy')
]
可以发现,网络的大致结构与逐步传播基本相同,所有的无状态的层,例如 Conv2d,都会被 layer.SeqToANNContainer 包装。前向传播的实现不需要时
间上的循环:
def forward(self, x: torch.Tensor):
x = x.permute(1, 0, 2, 3, 4) # [N, T, 2, H, W] -> [T, N, 2, H, W]
out_spikes = self.fc(self.conv(x)) # shape = [T, N, 110]
return self.vote(out_spikes.mean(0))
代码细节¶
为了便于调试,让我们在代码中加入大量的超参数:
parser = argparse.ArgumentParser(description='Classify DVS128 Gesture')
parser.add_argument('-T', default=16, type=int, help='simulating time-steps')
parser.add_argument('-device', default='cuda:0', help='device')
parser.add_argument('-b', default=16, type=int, help='batch size')
parser.add_argument('-epochs', default=64, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('-j', default=4, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('-channels', default=128, type=int, help='channels of Conv2d in SNN')
parser.add_argument('-data_dir', type=str, help='root dir of DVS128 Gesture dataset')
parser.add_argument('-out_dir', type=str, help='root dir for saving logs and checkpoint')
parser.add_argument('-resume', type=str, help='resume from the checkpoint path')
parser.add_argument('-amp', action='store_true', help='automatic mixed precision training')
parser.add_argument('-cupy', action='store_true', help='use CUDA neuron and multi-step forward mode')
parser.add_argument('-opt', type=str, help='use which optimizer. SDG or Adam')
parser.add_argument('-lr', default=0.001, type=float, help='learning rate')
parser.add_argument('-momentum', default=0.9, type=float, help='momentum for SGD')
parser.add_argument('-lr_scheduler', default='CosALR', type=str, help='use which schedule. StepLR or CosALR')
parser.add_argument('-step_size', default=32, type=float, help='step_size for StepLR')
parser.add_argument('-gamma', default=0.1, type=float, help='gamma for StepLR')
parser.add_argument('-T_max', default=32, type=int, help='T_max for CosineAnnealingLR')
使用混合精度训练,可以大幅度提升速度,减少显存消耗:
if args.amp:
with amp.autocast():
out_fr = net(frame)
loss = F.mse_loss(out_fr, label_onehot)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
out_fr = net(frame)
loss = F.mse_loss(out_fr, label_onehot)
loss.backward()
optimizer.step()
我们的网络将支持断点续训:
#...........
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
net.load_state_dict(checkpoint['net'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
start_epoch = checkpoint['epoch'] + 1
max_test_acc = checkpoint['max_test_acc']
# ...
for epoch in range(start_epoch, args.epochs):
# train...
# test...
checkpoint = {
'net': net.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch,
'max_test_acc': max_test_acc
}
# ...
torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_latest.pth'))
运行训练¶
完整的代码位于 classify_dvsg.py。
我们在`Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz` 的CPU和 GeForce RTX 2080 Ti 的GPU上运行网络。我们使用的超参数几乎与原文 1
一致,但略有区别:我们使用 T=16 而原文 1 使用 T=20,因为 GeForce RTX 2080 Ti 的12G显存不够使用 T=20;此外,我们还
开启了自动混合精度训练,正确率可能会略微低于全精度训练。
运行一下逐步模式的网络:
(test-env) root@de41f92009cf3011eb0ac59057a81652d2d0-fangw1714-0:/userhome/test# python -m spikingjelly.clock_driven.examples.classify_dvsg -data_dir /userhome/datasets/DVS128Gesture -out_dir ./logs -amp -opt Adam -device cuda:0 -lr_scheduler CosALR -T_max 64 -epochs 1024
Namespace(T=16, T_max=64, amp=True, b=16, cupy=False, channels=128, data_dir='/userhome/datasets/DVS128Gesture', device='cuda:0', epochs=1024, gamma=0.1, j=4, lr=0.001, lr_scheduler='CosALR', momentum=0.9, opt='Adam', out_dir='./logs', resume=None, step_size=32)
PythonNet(
(conv): Sequential(
(0): Conv2d(2, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(5): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(17): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(18): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(19): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Dropout(p=0.5)
(2): Linear(in_features=2048, out_features=512, bias=False)
(3): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
(4): Dropout(p=0.5)
(5): Linear(in_features=512, out_features=110, bias=False)
(6): LIFNode(
v_threshold=1.0, v_reset=0.0, tau=2.0
(surrogate_function): ATan(alpha=2.0, spiking=True)
)
)
(vote): VotingLayer(
(voting): AvgPool1d(kernel_size=(10,), stride=(10,), padding=(0,))
)
)
The directory [/userhome/datasets/DVS128Gesture/frames_number_16_split_by_number] already exists.
The directory [/userhome/datasets/DVS128Gesture/frames_number_16_split_by_number] already exists.
Mkdir ./logs/T_16_b_16_c_128_Adam_lr_0.001_CosALR_64_amp.
Namespace(T=16, T_max=64, amp=True, b=16, cupy=False, channels=128, data_dir='/userhome/datasets/DVS128Gesture', device='cuda:0', epochs=1024, gamma=0.1, j=4, lr=0.001, lr_scheduler='CosALR', momentum=0.9, opt='Adam', out_dir='./logs', resume=None, step_size=32)
epoch=0, train_loss=0.06680945929599134, train_acc=0.4032534246575342, test_loss=0.04891310722774102, test_acc=0.6180555555555556, max_test_acc=0.6180555555555556, total_time=27.759592294692993
可以发现,一个epoch用时为27.76s。中断训练,让我们换成速度更快的模式:
(test-env) root@de41f92009cf3011eb0ac59057a81652d2d0-fangw1714-0:/userhome/test# python -m spikingjelly.clock_driven.examples.classify_dvsg -data_dir /userhome/datasets/DVS128Gesture -out_dir ./logs -amp -opt Adam -device cuda:0 -lr_scheduler CosALR -T_max 64 -cupy -epochs 1024
Namespace(T=16, T_max=64, amp=True, b=16, cupy=True, channels=128, data_dir='/userhome/datasets/DVS128Gesture', device='cuda:0', epochs=1024, gamma=0.1, j=4, lr=0.001, lr_scheduler='CosALR', momentum=0.9, opt='Adam', out_dir='./logs', resume=None, step_size=32)
CextNet(
(conv): Sequential(
(0): SeqToANNContainer(
(module): Sequential(
(0): Conv2d(2, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(2): SeqToANNContainer(
(module): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(3): SeqToANNContainer(
(module): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(5): SeqToANNContainer(
(module): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(6): SeqToANNContainer(
(module): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(8): SeqToANNContainer(
(module): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(9): SeqToANNContainer(
(module): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(10): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(11): SeqToANNContainer(
(module): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(12): SeqToANNContainer(
(module): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(13): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(14): SeqToANNContainer(
(module): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
(fc): Sequential(
(0): Flatten(start_dim=2, end_dim=-1)
(1): MultiStepDropout(p=0.5)
(2): SeqToANNContainer(
(module): Linear(in_features=2048, out_features=512, bias=False)
)
(3): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
(4): MultiStepDropout(p=0.5)
(5): SeqToANNContainer(
(module): Linear(in_features=512, out_features=110, bias=False)
)
(6): MultiStepLIFNode(v_threshold=1.0, v_reset=0.0, detach_reset=True, surrogate_function=ATan, alpha=2.0 tau=2.0)
)
(vote): VotingLayer(
(voting): AvgPool1d(kernel_size=(10,), stride=(10,), padding=(0,))
)
)
The directory [/userhome/datasets/DVS128Gesture/frames_number_16_split_by_number] already exists.
The directory [/userhome/datasets/DVS128Gesture/frames_number_16_split_by_number] already exists.
Mkdir ./logs/T_16_b_16_c_128_Adam_lr_0.001_CosALR_64_amp_cupy.
Namespace(T=16, T_max=64, amp=True, b=16, cupy=True, channels=128, data_dir='/userhome/datasets/DVS128Gesture', device='cuda:0', epochs=1024, gamma=0.1, j=4, lr=0.001, lr_scheduler='CosALR', momentum=0.9, opt='Adam', out_dir='./logs', resume=None, step_size=32)
epoch=0, train_loss=0.06690179117738385, train_acc=0.4092465753424658, test_loss=0.049108295158172645, test_acc=0.6145833333333334, max_test_acc=0.6145833333333334, total_time=18.169376373291016
...
Namespace(T=16, T_max=64, amp=True, b=16, cupy=True, channels=128, data_dir='/userhome/datasets/DVS128Gesture', device='cuda:0', epochs=1024, gamma=0.1, j=4, lr=0.001, lr_scheduler='CosALR', momentum=0.9, opt='Adam', out_dir='./logs', resume=None, step_size=32)
epoch=255, train_loss=0.000212281955773102445, train_acc=1.0, test_loss=0.008522209396485576, test_acc=0.9375, max_test_acc=0.9618055555555556, total_time=17.49005389213562
训练一个epoch耗时为18.17s,比逐步传播的27.76s快了约10s。训练256个epoch,我们可以达到最高96.18%的正确率,得到的训练曲线如下:



