Propagation Pattern¶
Authors: fangwei123456
Single-Step and Multi-Step¶
Most modules in SpikingJelly (except for spikingjelly.clock_driven.rnn), e.g., spikingjelly.clock_driven.layer.Dropout, don’t have a MultiStep prefix. These modules’ forward functions define a single-step forward:
Input \(X_{t}\), output \(Y_{t}\)
If a module has a MultiStep prefix, e.g., spikingjelly.clock_driven.layer.MultiStepDropout, then this module’s forward function defines the multi-step forward:
Input \(X_{t}, t=0,1,...,T-1\), output \(Y_{t}, t=0,1,...,T-1\)
A single-step module can be easily packaged as a multi-step module. For example, we can use spikingjelly.clock_driven.layer.MultiStepContainer, which contains the origin module as a sub-module and implements the loop in time-steps in its forward function:
class MultiStepContainer(nn.Module):
def __init__(self, module: nn.Module):
super().__init__()
self.module = module
def forward(self, x_seq: torch.Tensor):
y_seq = []
for t in range(x_seq.shape[0]):
y_seq.append(self.module(x_seq[t]))
y_seq[-1].unsqueeze_(0)
return torch.cat(y_seq, 0)
def reset(self):
if hasattr(self.module, 'reset'):
self.module.reset()
Let us use spikingjelly.clock_driven.layer.MultiStepContainer to implement a multi-step IF neuron:
from spikingjelly.clock_driven import neuron, layer
import torch
neuron_num = 4
T = 8
if_node = neuron.IFNode()
x = torch.rand([T, neuron_num]) * 2
for t in range(T):
print(f'if_node output spikes at t={t}', if_node(x[t]))
if_node.reset()
ms_if_node = layer.MultiStepContainer(if_node)
print("multi step if_node output spikes\n", ms_if_node(x))
ms_if_node.reset()
The outputs are:
if_node output spikes at t=0 tensor([1., 1., 1., 0.])
if_node output spikes at t=1 tensor([0., 0., 0., 1.])
if_node output spikes at t=2 tensor([1., 1., 1., 1.])
if_node output spikes at t=3 tensor([0., 0., 1., 0.])
if_node output spikes at t=4 tensor([1., 1., 1., 1.])
if_node output spikes at t=5 tensor([1., 0., 0., 0.])
if_node output spikes at t=6 tensor([1., 0., 1., 1.])
if_node output spikes at t=7 tensor([1., 1., 1., 0.])
multi step if_node output spikes
tensor([[1., 1., 1., 0.],
[0., 0., 0., 1.],
[1., 1., 1., 1.],
[0., 0., 1., 0.],
[1., 1., 1., 1.],
[1., 0., 0., 0.],
[1., 0., 1., 1.],
[1., 1., 1., 0.]])
We can find that the single-step module and the multi-step module have the identical outputs.
Step-by-step and Layer-by-Layer¶
In the previous tutorials and examples, we run the SNNs step-by-step, e.g.,:
if_node = neuron.IFNode()
x = torch.rand([T, neuron_num]) * 2
for t in range(T):
print(f'if_node output spikes at t={t}', if_node(x[t]))
step-by-step means that during the forward propagation, we firstly calculate the SNN’s outputs \(Y_{0}\) at \(t=0\), then we calculate the SNN’s outputs \(Y_{1}\) at \(t=1\),…, and we can get the outputs at all time-steps \(Y_{t}, t=0,1,...,T-1\). The followed code is a step-by-step example (we suppose M0, M1, M2 are single-step modules):
net = nn.Sequential(M0, M1, M2)
for t in range(T):
Y[t] = net(X[t])
The computation graph of forward propagation is built as followed:
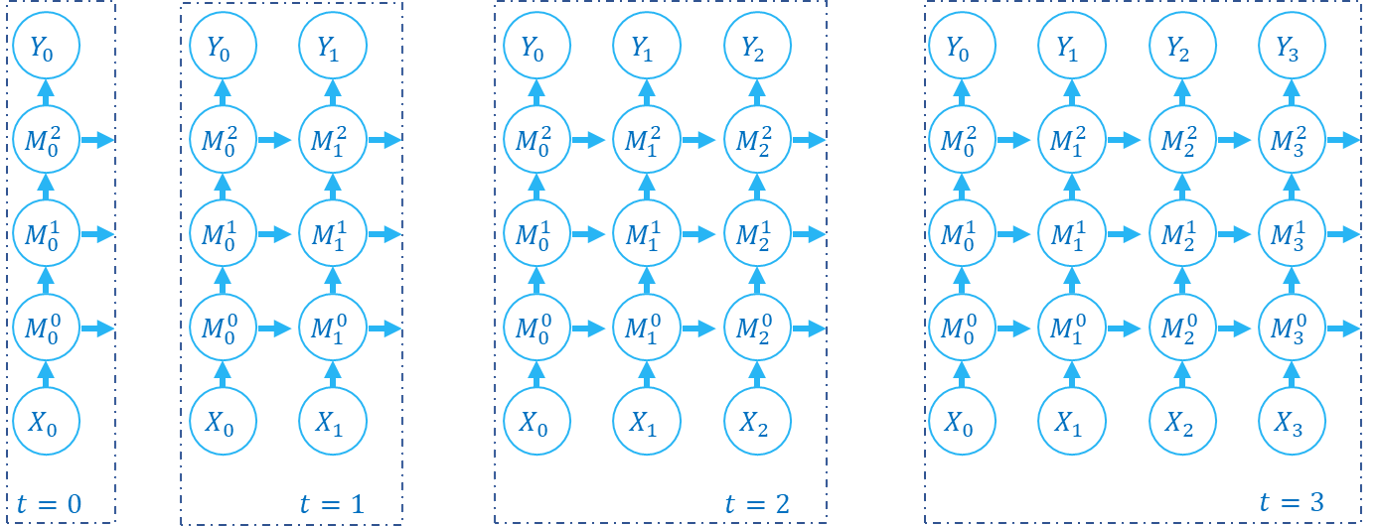
The forward propagation of SNN and RNN is along both spatial domain and temporal domain. step-by-step calculates states of the whole network step by step. We can also use an another order, which is layer-by-layer. layer-by-layer calculates states layer-by-layer. The followed code is a layer-by-layer example (we suppose M0, M1, M2 are multi-step modules):
net = nn.Sequential(M0, M1, M2)
Y = net(X)
The computation graph of forward propagation is built as followed:

The layer-by-layer method is widely used in RNN and SNN, e.g., Low-activity supervised convolutional spiking neural networks applied to speech commands recognition calculates outputs of each layer to implement a temporal convolution. Their codes are availble at https://github.com/romainzimmer/s2net.
The difference between step-by-step and layer-by-layer is the order of traverse the computation graph. The computed results of both methods are exactly same. However, step-by-step has more degree of parallelism. When a layer is stateless, e.g., torch.nn.Linear, the step-by-step method may calculate as:
for t in range(T):
y[t] = fc(x[t]) # x.shape=[T, batch_size, in_features]
The layer-by-layer method can calculate parallelly:
y = fc(x) # x.shape=[T, batch_size, in_features]
For a stateless layer, we can concatenate inputs shape=[T, batch_size, ...] at time dimension as shape=[T * batch_size, ...] to avoid loop in time-steps. spikingjelly.clock_driven.layer.SeqToANNContainer has provided such a function in its forward. We can directly use this module:
with torch.no_grad():
T = 16
batch_size = 8
x = torch.rand([T, batch_size, 4])
fc = SeqToANNContainer(nn.Linear(4, 2), nn.Linear(2, 3))
print(fc(x).shape)
The outputs are
torch.Size([16, 8, 3])
The outputs have shape=[T, batch_size, ...] and can be directly fed to the next layer.