自连接和有状态突触
本教程作者: fangwei123456
自连接模块
自连接指的是从输出到输入的连接,例如 [1] 一文中的SRNN(recurrent networks of spiking neurons),如下图所示:
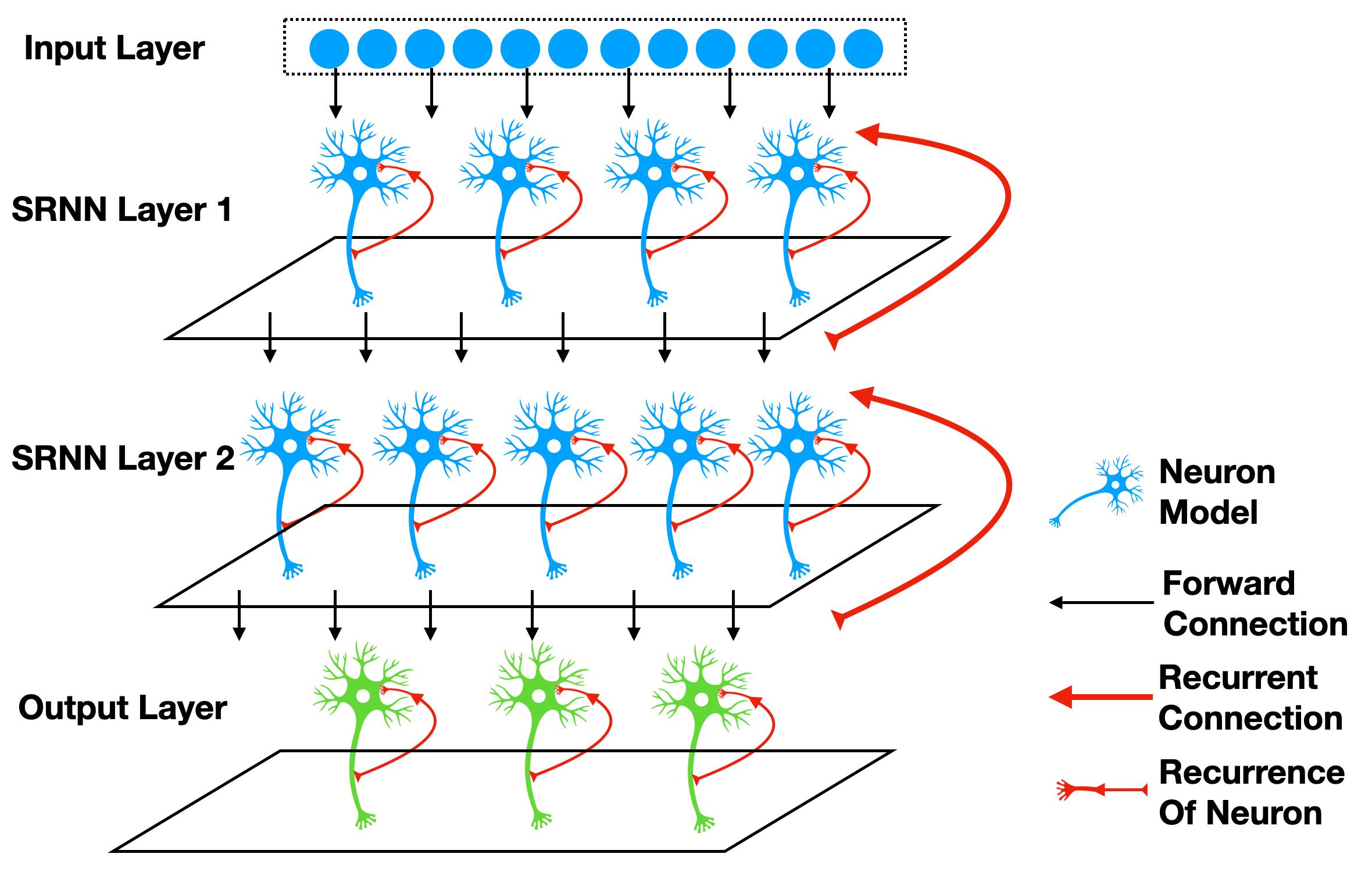
使用SpikingJelly框架很容易构建出带有自连接的模块。考虑最简单的一种情况,我们给神经元增加一个回路,使得它在 \(t\) 时刻的输出 \(s[t]\),会与下一个时刻的外界输入 \(x[t+1]\) 相加,共同作为输入。这可以由 spikingjelly.activation_based.layer.ElementWiseRecurrentContainer 轻松实现。 ElementWiseRecurrentContainer 是一个包装器,给任意的 sub_module 增加一个额外的自连接。连接的形式可以使用用户自定义的逐元素函数操作 \(z=f(x, y)\) 来实现。记 \(x[t]\) 为
\(t\) 时刻整个模块的输入,\(i[t]\) 和 \(y[t]\) 是
sub_module的输入和输出(注意 \(y[t]\) 同时也是整个模块的输出),则
其中 \(f\) 是用户自定义的逐元素操作。默认 \(y[-1] = 0\)。
现在让我们用 ElementWiseRecurrentContainer 来包装一个IF神经元,逐元素操作设置为加法,因而
我们给与 \(x[t]=[1.5, 0, ..., 0]\) 的输入:
import torch
from spikingjelly.activation_based import layer, functional, neuron
T = 8
N = 1
def element_wise_add(x, y):
return x + y
net = layer.ElementWiseRecurrentContainer(neuron.IFNode(), element_wise_add)
print(net)
x = torch.zeros([T, N])
x[0] = 1.5
for t in range(T):
print(t, f'x[t]={x[t]}, s[t]={net(x[t])}')
functional.reset_net(net)
输出为:
ElementWiseRecurrentContainer(
element-wise function=<function element_wise_add at 0x00000158FC15ACA0>, step_mode=s
(sub_module): IFNode(
v_threshold=1.0, v_reset=0.0, detach_reset=False, step_mode=s, backend=torch
(surrogate_function): Sigmoid(alpha=4.0, spiking=True)
)
)
0 x[t]=tensor([1.5000]), s[t]=tensor([1.])
1 x[t]=tensor([0.]), s[t]=tensor([1.])
2 x[t]=tensor([0.]), s[t]=tensor([1.])
3 x[t]=tensor([0.]), s[t]=tensor([1.])
4 x[t]=tensor([0.]), s[t]=tensor([1.])
5 x[t]=tensor([0.]), s[t]=tensor([1.])
6 x[t]=tensor([0.]), s[t]=tensor([1.])
7 x[t]=tensor([0.]), s[t]=tensor([1.])
可以发现,由于存在自连接,即便 \(t \ge 1\) 时 \(x[t]=0\),由于输出的脉冲能传回到输入,神经元也能持续释放脉冲。
可以使用 spikingjelly.activation_based.layer.LinearRecurrentContainer 实现更复杂的全连接形式的自连接。
有状态的突触
[2] [3] 等文章使用有状态的突触。将 spikingjelly.activation_based.layer.SynapseFilter 放在普通无状
态突触的后面,对突触输出的电流进行滤波,就可以得到有状态的突触,例如:
import torch
import torch.nn as nn
from spikingjelly.activation_based import layer, functional, neuron
stateful_conv = nn.Sequential(
layer.Conv2d(3, 16, kernel_size=3, padding=1, stride=1),
layer.SynapseFilter(tau=100.)
)
Sequential FashionMNIST上的对比实验
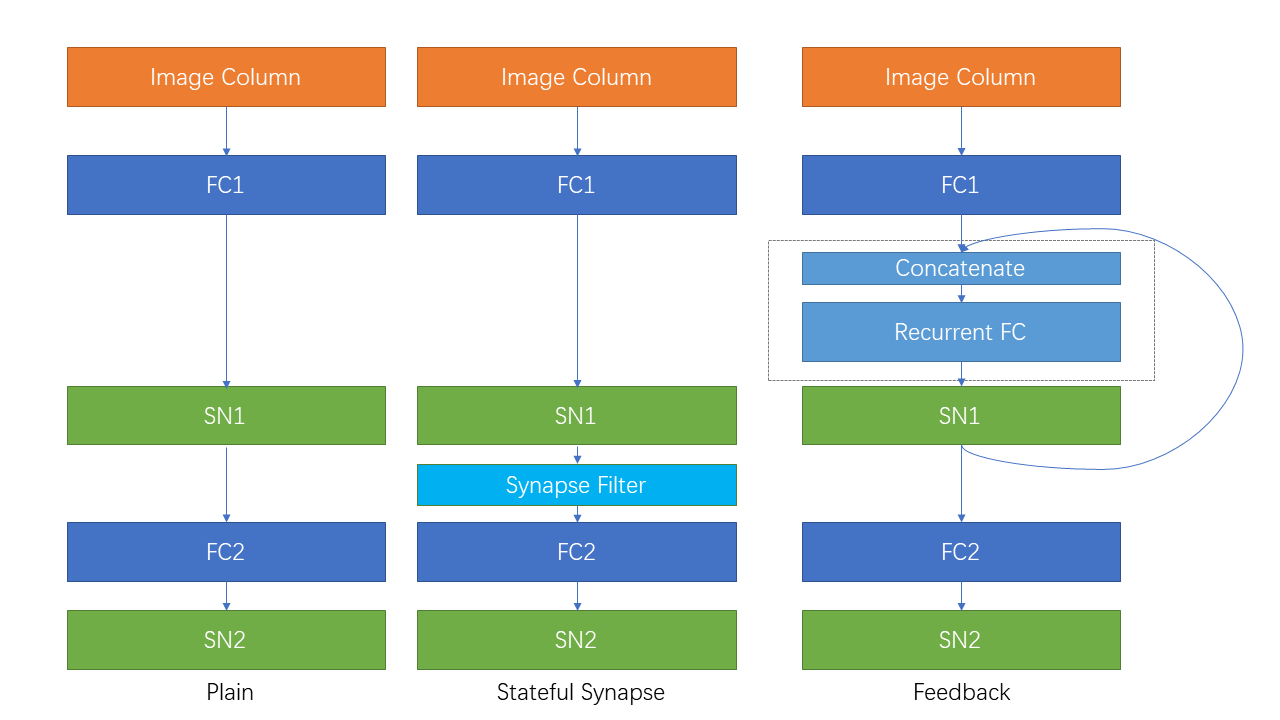
接下来让我们在Sequential FashionMNIST上做一个简单的实验,验证自连接和有状态突触是否有助于改善网络的记忆能力。Sequential FashionMNIST指的是 将原始的FashionMNIST图片一行一行或者一列一列,而不是整个图片,作为输入。在这种情况下,网络必须具有一定的记忆能力,才能做出正确的分类。我们将会把 图片一列一列的输入,这样对网络而言,就像是从左到右“阅读”一样,如下图所示:
下图中展示了被读入的列:

首先导入相关的包:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.datasets
from spikingjelly.activation_based import neuron, surrogate, layer, functional
from torch.cuda import amp
import os, argparse
from torch.utils.tensorboard import SummaryWriter
import time
import datetime
import sys
我们定义一个普通的前馈网络 PlainNet:
class PlainNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
layer.Linear(28, 32),
neuron.IFNode(surrogate_function=surrogate.ATan()),
layer.Linear(32, 10),
neuron.IFNode(surrogate_function=surrogate.ATan())
)
def forward(self, x: torch.Tensor):
return self.fc(x).mean(0)
我们在 PlainNet 的第一层脉冲神经元后增加一个 spikingjelly.activation_based.layer.SynapseFilter,得到一个新的网络 StatefulSynapseNet:
class StatefulSynapseNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
layer.Linear(28, 32),
neuron.IFNode(surrogate_function=surrogate.ATan()),
layer.SynapseFilter(tau=2., learnable=True),
layer.Linear(32, 10),
neuron.IFNode(surrogate_function=surrogate.ATan())
)
def forward(self, x: torch.Tensor):
return self.fc(x).mean(0)
我们给 PlainNet 的第一层脉冲神经元增加一个反馈连接 spikingjelly.activation_based.layer.LinearRecurrentContainer 得到 FeedBackNet:
class FeedBackNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
layer.Linear(28, 32),
layer.LinearRecurrentContainer(
neuron.IFNode(surrogate_function=surrogate.ATan(), detach_reset=True),
in_features=32, out_features=32, bias=True
),
layer.Linear(32, 10),
neuron.IFNode(surrogate_function=surrogate.ATan())
)
def forward(self, x: torch.Tensor):
return self.fc(x).mean(0)
下图展示了3种网络的结构:
完整的代码位于 spikingjelly.activation_based.examples.rsnn_sequential_fmnist。我们可以通过命令行直接运行。运行参数为:
usage: rsnn_sequential_fmnist.py [-h] [-model MODEL] [-device DEVICE] [-b B] [-epochs N] [-j N] [-data-dir DATA_DIR] [-out-dir OUT_DIR] [-resume RESUME] [-amp] [-cupy] [-opt OPT] [-momentum MOMENTUM] [-lr LR]
Classify Sequential Fashion-MNIST
optional arguments:
-h, --help show this help message and exit
-model MODEL use which model, "plain", "ss" (StatefulSynapseNet) or "fb" (FeedBackNet)
-device DEVICE device
-b B batch size
-epochs N number of total epochs to run
-j N number of data loading workers (default: 4)
-data-dir DATA_DIR root dir of Fashion-MNIST dataset
-out-dir OUT_DIR root dir for saving logs and checkpoint
-resume RESUME resume from the checkpoint path
-amp automatic mixed precision training
-cupy use cupy backend
-opt OPT use which optimizer. SDG or Adam
-momentum MOMENTUM momentum for SGD
-lr LR learning rate
分别训练3个模型:
python -m spikingjelly.activation_based.examples.rsnn_sequential_fmnist -device cuda:0 -b 256 -epochs 64 -data-dir /datasets/FashionMNIST/ -amp -cupy -opt sgd -lr 0.1 -j 8 -model plain
python -m spikingjelly.activation_based.examples.rsnn_sequential_fmnist -device cuda:0 -b 256 -epochs 64 -data-dir /datasets/FashionMNIST/ -amp -cupy -opt sgd -lr 0.1 -j 8 -model fb
python -m spikingjelly.activation_based.examples.rsnn_sequential_fmnist -device cuda:0 -b 256 -epochs 64 -data-dir /datasets/FashionMNIST/ -amp -cupy -opt sgd -lr 0.1 -j 8 -model ss
下图展示了3种网络的训练曲线:


可以发现, StatefulSynapseNet 和 FeedBackNet 的性能都高于 PlainNet,表明自连接和有状态突触都有助于提升网络的记忆能力。