FlexSN#
本页作者:黄一凡 (AllenYolk)、wei.fang
English version: FlexSN
本教程聚焦 FlexSN 的使用。FlexSN 可根据用户自定义的单步神经元动力学函数 core 生成高性能多步内核。
若你尚未阅读 Triton 后端基础,建议先阅读 Triton 后端 ,了解 Triton 神经元内核的启用方式与基本约束。
使用 FlexSN 自定义 Triton 神经元内核#
用函数描述神经元动力学#
绝大多数脉冲神经元模型在一个离散时间步上的动力学可以描述为:
其中 \(Y_i\) 表示输出,\(V_i\) 表示状态变量,\(X_i\) 表示输入。该公式可以用 PyTorch 函数描述:
def single_step_inference(x1, x2, ..., v1, v2, ...):
...
return y1, y2, ..., v1_updated, v2_updated, ...
其中 x1, x2, ... 表示输入, v1, v2, ... 表示状态变量, y1, y2, ... 表示输出,而 v1_updated, v2_updated, ... 表示更新后的状态变量(与 v1, v2, ... 对应)。例如,输入不衰减的软重置 LIF 神经元( tau=2 , v_th=1.0 ,sigmoid 替代函数 )可以描述为:
from spikingjelly.activation_based import surrogate
tau = 2.0 # time constant
v_th = 1.0 # threshold
spike_fn = surrogate.Sigmoid()
def lif_single_step_inference(x, v):
h = (1 - 1/tau) * v + x
s = spike_fn(h - v_th)
v = h - s * v_th
return s, v
这个例子中,输入、输出和状态变量的数量都是1;而对于更复杂的神经元模型,输入、输出和状态变量的数量都可能是多个。另外,此处的模型超参数 tau , v_th 和 spike_fn 都是固定下来的全局变量。为了灵活配置超参数,可以使用 函数闭包 :
from spikingjelly.activation_based import surrogate
def lif_single_step_inference_closure(tau=2., v_th=1., spike_fn=surrogate.Sigmoid()):
def lif_single_step_inference(x, v):
h = (1 - 1/tau) * v + x
s = spike_fn(h - v_th)
v = h - s * v_th
return s, v
return lif_single_step_inference
f = lif_single_step_inference_closure(tau=99., v_th=0.5)
FlexSN 使用流程#
以如下的自定义脉冲神经元为例:
import torch
from spikingjelly.activation_based import surrogate
def complicated_lif_core_generator(beta: float, gamma: float, spike_fn=surrogate.ATan()):
def complicated_lif_core(
x: torch.Tensor, y: torch.Tensor, v: torch.Tensor, rho: torch.Tensor
):
h = beta*v + x
s1 = spike_fn(h - (rho+1.)) # spike, with threshold adaptation
s2 = spike_fn(h - 1.) # spike, without threshold adaptation
rho = gamma*rho + s1 # adaptation variable update
v1 = h * (1.-s1) # hard reset
v2 = h - s2 # soft reset
yy = torch.sigmoid(y) # modulation factor
v = v1*yy + v2 * (1.-yy) # modulated reset
return s1, s2, v, rho
return complicated_lif_core
该模型有两个输入 x, y ,两个输出 s1, s2 ,以及两个状态变量 v, rho 。不同变量之间的依赖关系如下图所示:
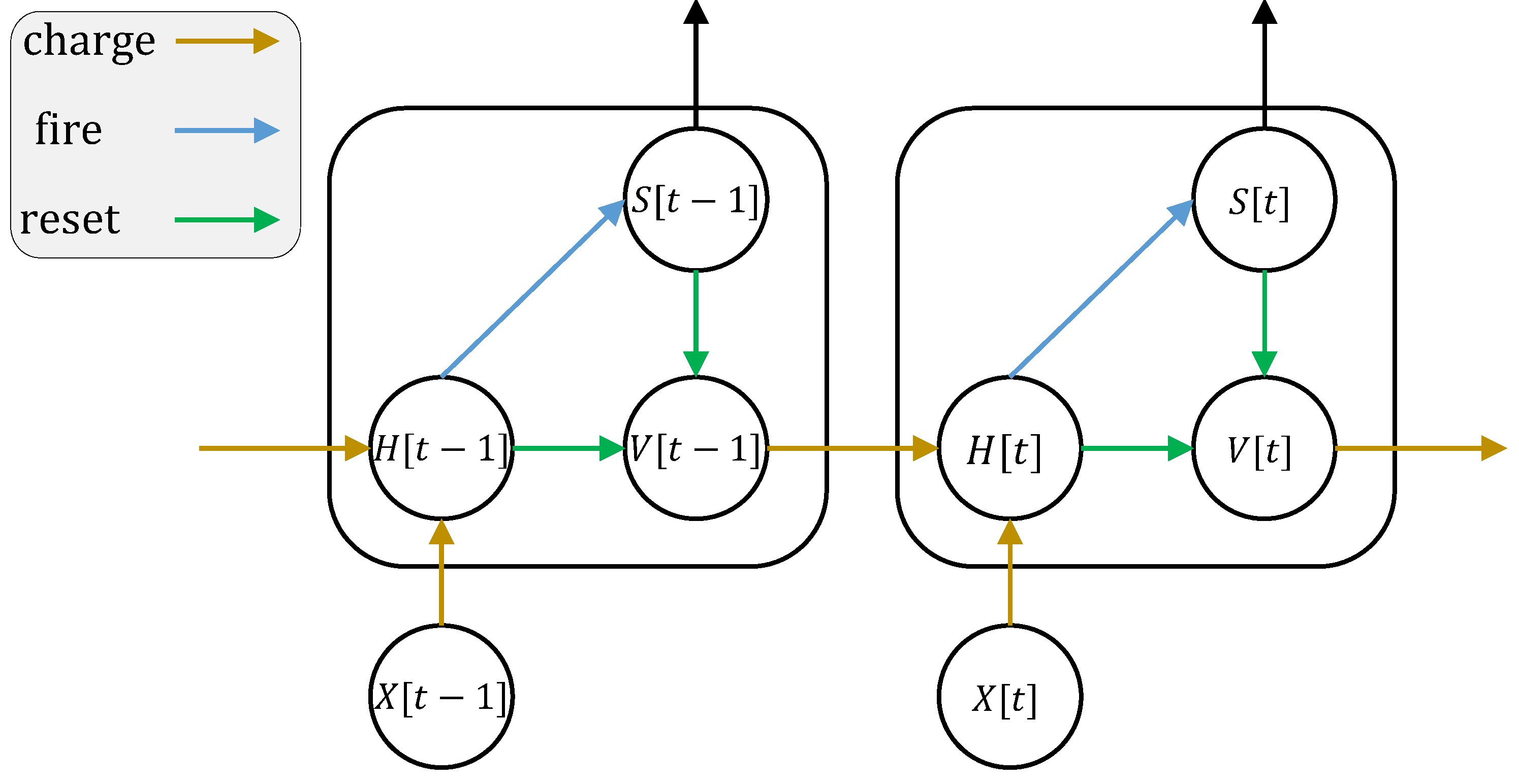
为了生成多步 Triton 内核,使用 FlexSN 模块进行包装:
from spikingjelly.activation_based import neuron
f = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="inductor",
store_state_seqs=True,
)
x = torch.randn([16, 3, 32, 32], device="cuda")
y = torch.randn([16, 3, 32, 32], device="cuda")
s1, s2 = f(x, y)
v, rho = f.state_seqs
print(s1.mean()) # tensor(0.0821, device='cuda:0', grad_fn=<MeanBackward0>)
print(s2.mean()) # tensor(0.1494, device='cuda:0', grad_fn=<MeanBackward0>)
print(v.mean()) # tensor(-0.2750, device='cuda:0', grad_fn=<MeanBackward0>)
print(rho.mean()) # tensor(0.4842, device='cuda:0', grad_fn=<MeanBackward0>)
FlexSN 的构造需要以下关键参数:
core:描述单步神经元动力学的函数,签名为[*inputs, *states] -> [*outputs, *states]。num_inputs, num_states, num_outputs:输入、状态变量和输出的个数。应与core签名的情况相一致。example_inputs:core的参数示例。FlexSN内部将使用这些示例输入调用core,从而捕获计算图。若为None(默认),则自动生成num_inputs + num_states个仅含一个元素的张量作为示例输入。example_outputs: 可选,core的单步输出模板。它主要在空序列输入(T == 0)时用于确定输出张量的形状和 dtype;对"triton"/"inductor"路径而言,若提供该参数,则每个模板张量都需要与第一个example_inputs张量的单步形状和 dtype 相匹配。requires_grad:core参数是否需要求梯度。默认值为None,含义为“所有参数都需要梯度”(即等价于全为True)。step_mode, backend:类似于其他神经元模块,这两个参数决定了步进模式和后端。"torch"后端始终可用;"triton"、"inductor"和"hop"后端只在step_mode="m"时有效。store_state_seqs:类似于其他神经元的store_v_seq,该参数决定是否保存状态序列。若为True,则可通过state_seqs属性获取上一次运行的状态序列:该属性是一个列表,列表的每个元素对应着某个状态的序列。FlexSN当然也支持反向传播,如下面的代码片段所示:
n_inductor = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="inductor",
store_state_seqs=True,
)
n_torch = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="torch",
store_state_seqs=True,
)
x = torch.randn([16, 3, 32, 32], device="cuda")
y = torch.randn([16, 3, 32, 32], device="cuda")
x_inductor = x.clone().requires_grad_(True)
y_inductor = y.clone().requires_grad_(True)
x_torch = x.clone().requires_grad_(True)
y_torch = y.clone().requires_grad_(True)
s1_inductor, s2_inductor = n_inductor(x_inductor, y_inductor)
s1_torch, s2_torch = n_torch(x_torch, y_torch)
grad = torch.randn_like(s1_inductor)
s1_inductor.backward(grad)
s1_torch.backward(grad)
v_inductor, rho_inductor = n_inductor.state_seqs
v_torch, rho_torch = n_torch.state_seqs
assert torch.allclose(s1_inductor, s1_torch)
assert torch.allclose(s2_inductor, s2_torch)
assert torch.allclose(x_inductor.grad, x_torch.grad, atol=1e-6, rtol=1e-6)
assert torch.allclose(y_inductor.grad, y_torch.grad, atol=1e-6, rtol=1e-6)
assert torch.allclose(v_inductor, v_torch, atol=1e-6, rtol=1e-6)
assert torch.allclose(rho_inductor, rho_torch)
print(s1_inductor.mean())
print(s2_inductor.mean())
print(x_inductor.grad.mean())
print(y_inductor.grad.mean())
print(v_inductor.mean())
print(rho_inductor.mean())
assert 全部通过,输出如下所示。这证明: FlexSN 使用的 Triton scan 内核与原始 PyTorch 函数在前向和反向传播时都具有等价性。
tensor(0.0821, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.1494, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.0007, device='cuda:0')
tensor(6.2995e-05, device='cuda:0')
tensor(-0.2750, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.4842, device='cuda:0', grad_fn=<MeanBackward0>)
使用上述流程,用户可以用极少的代码量得到 Triton 加速神经元模型。相比曾经的 auto_cuda 模块(见 编写CUPY神经元 ), FlexSN 更加灵活、泛用。
注意
在上方的例子中,状态变量 v 和 rho 采用了 默认的全零初始化方式 。用户可以重写 init_states() 方法,从而改变状态初始化规则。该方法的原始定义如下,其中 *args 代表 forward() 方法的参数:
class FlexSN(base.MemoryModule):
...
@staticmethod
def init_states(num_states: int, step_mode: str, *args) -> List[torch.Tensor]:
if step_mode == "s":
return [torch.zeros_like(args[0]) for _ in range(num_states)]
elif step_mode == "m":
return [torch.zeros_like(args[0][0]) for _ in range(num_states)]
else:
raise ValueError(f"Unsupported step mode: {step_mode}")
详见 FlexSN.init_states 。
注意
FlexSN 实现了 SpikingJelly 神经元模块的大多数功能。
若想用轻量化、透明化、函数式的方式直接调用生成好的内核,请使用 FlexSNKernel 。
警告
在使用 FlexSN 时,需注意:
"torch"后端可以在 CPU 或 GPU 上运行;"triton"与"inductor"后端需要 GPU,且"triton"/"inductor"/"hop"后端都仅支持多步运行模式step_mode="m"。PyTorch 后端是通过反复调用
core来实现的。FlexSN完成一次模拟之后,需要调用reset()方法来重置神经元状态。
兼容 torch.compile#
主要特点:
FlexSN 支持 torch.compile ,可与外层网络联合编译,实现跨层算子融合。 FlexSN 推理和训练都内置了专用 Triton 核;在专用 kernel 不可用时,仍保留 final-state 快路径与 HOP/eager fallback。
注意
最小示例#
推理:
import torch
import torch.nn as nn
from spikingjelly.activation_based.neuron.flexsn import FlexSN
def lif_core(x: torch.Tensor, v: torch.Tensor):
tau, v_th = 2.0, 1.0
h = v + (x - v) / tau
s = (h >= v_th).to(h.dtype)
return s, h * (1.0 - s)
neuron = FlexSN(core=lif_core, num_inputs=1, num_states=1,
num_outputs=1, step_mode="m", backend="inductor").cuda()
x = torch.randn(8, 64, 512, device="cuda")
with torch.no_grad():
out = neuron(x) # 直接调用,无需 torch.compile
# 可选:套 torch.compile 实现与外层 Linear 的跨层融合
model = nn.Sequential(nn.Linear(512, 512), neuron, nn.Linear(512, 512)).cuda()
model = torch.compile(model, fullgraph=True)
out = model(x)
训练:
import torch
from spikingjelly.activation_based import surrogate
from spikingjelly.activation_based.neuron.flexsn import FlexSN
sg = surrogate.Sigmoid(alpha=4.0)
def lif_core_sg(x: torch.Tensor, v: torch.Tensor):
tau, v_th = 2.0, 1.0
h = v + (x - v) / tau
s = sg(h - v_th) # Sigmoid surrogate gradient
return s, h * (1.0 - s)
neuron = FlexSN(core=lif_core_sg, num_inputs=1, num_states=1,
num_outputs=1, step_mode="m", backend="inductor").cuda()
x = torch.randn(8, 64, 512, device="cuda", requires_grad=True)
out = neuron(x)
out.sum().backward() # BPTT via Triton fwd+bwd 核
print(x.grad.shape) # [8, 64, 512]
上面两种场景都不强制依赖 torch.compile 。不套时, "triton" 后端与
"inductor" 后端依然直接使用同一套专用 Triton scan kernel;套上时,
FlexSN 会通过 custom-op 路径继续调度这些 Triton kernel,同时让外层
Linear / Conv 一起进入编译图。
支持的后端#
后端 |
设备 |
执行路径 |
典型用途 / 备注 |
|---|---|---|---|
|
CPU / CUDA |
纯 PyTorch 多步循环 |
参考实现、调试、CPU 原型验证 |
|
CUDA |
同一条 Triton 执行路径 |
高性能路径 |
|
CPU / CUDA |
HOP / eager scan 路径 |
scan tracing、实验、fallback |
运行时行为#
在 backend="triton" 或 backend="inductor" 下:
推理阶段会先用
make_fx追踪core,生成带tl.static_range(T)时间循环的单个 Triton scan kernel。每次推理调用只触发一次 kernel launch,与T无关。训练阶段会同时追踪前向和反向,生成专用的 Triton 正向/反向 scan kernel。不套
torch.compile时,这已经是完整 Triton 路径。套上
torch.compile后,FlexSN 仍通过 opaque custom op 调度同一套 Triton kernel,同时允许外层网络联合编译。若
core使用了不受支持的算子,或者 Triton kernel 构建失败,则会自动回退到 HOP/eager-scan 路径。
实践建议:
做 CPU 工作、调试、验证语义时,用
"torch"后端。真正做高性能 GPU 运行时,用
"triton"后端或"inductor"后端。只有当你需要和外层模块做跨层融合时,再额外套
torch.compile。
算子覆盖#
FX_TO_TRITON 映射表目前覆盖以下 ATen 算子(推理和训练路径均支持):
类别 |
算子 |
|---|---|
四则运算 |
|
超越函数 |
|
取整 |
|
激活 / 阈值 |
|
比较 |
|
逻辑位运算 |
|
二元数学 |
|
clamp |
|
类型 / 构造 |
|
条件选择 |
|
反向专用 |
|
杂项 |
|
不在表内的算子(如矩阵运算、复杂控制流等)会触发 eager_scan fallback 并输出 WARNING 日志。