FlexSN#
Author: Yifan Huang (AllenYolk), wei.fang
中文版: FlexSN
This tutorial focuses on FlexSN. FlexSN can generate high-performance multi-step kernels from a user-defined single-step neuronal dynamics function core.
If you have not read the Triton backend basics yet, it is recommended to read Triton Backend first to understand the usage and constraints of predefined Triton neuron kernels.
Using FlexSN to Customize Triton Neuron Kernels#
Describing Neuronal Dynamics with Functions#
The discrete-time dynamics of most spiking neuron models can be described as:
where \(Y_i\) denotes outputs, \(V_i\) denotes state variables, and \(X_i\) denotes inputs. This equation can be described using a PyTorch function:
def single_step_inference(x1, x2, ..., v1, v2, ...):
...
return y1, y2, ..., v1_updated, v2_updated, ...
Here, x1, x2, ... represent inputs, v1, v2, ... represent state variables, y1, y2, ... represent outputs, and v1_updated, v2_updated, ... represent the updated state variables (corresponding to v1, v2, ...). For example, a soft-reset LIF neuron with non-decaying input (tau=2, v_th=1.0, sigmoid surrogate function) can be described as:
from spikingjelly.activation_based import surrogate
tau = 2.0 # time constant
v_th = 1.0 # threshold
spike_fn = surrogate.Sigmoid()
def lif_single_step_inference(x, v):
h = (1 - 1/tau) * v + x
s = spike_fn(h - v_th)
v = h - s * v_th
return s, v
In this example, there is only one input, one output, and one state variable. For more complex neuron models, however, there may be multiple inputs, outputs, and state variables. In addition, the model hyperparameters tau, v_th, and spike_fn here are fixed global variables. To flexibly configure hyperparameters, function closures can be used:
from spikingjelly.activation_based import surrogate
def lif_single_step_inference_closure(tau=2., v_th=1., spike_fn=surrogate.Sigmoid()):
def lif_single_step_inference(x, v):
h = (1 - 1/tau) * v + x
s = spike_fn(h - v_th)
v = h - s * v_th
return s, v
return lif_single_step_inference
f = lif_single_step_inference_closure(tau=99., v_th=0.5)
FlexSN Workflow#
Take the following customized spiking neuron as an example:
import torch
from spikingjelly.activation_based import surrogate
def complicated_lif_core_generator(beta: float, gamma: float, spike_fn=surrogate.ATan()):
def complicated_lif_core(
x: torch.Tensor, y: torch.Tensor, v: torch.Tensor, rho: torch.Tensor
):
h = beta*v + x
s1 = spike_fn(h - (rho+1.)) # spike, with threshold adaptation
s2 = spike_fn(h - 1.) # spike, without threshold adaptation
rho = gamma*rho + s1 # adaptation variable update
v1 = h * (1.-s1) # hard reset
v2 = h - s2 # soft reset
yy = torch.sigmoid(y) # modulation factor
v = v1*yy + v2 * (1.-yy) # modulated reset
return s1, s2, v, rho
return complicated_lif_core
This model has two inputs x, y, two outputs s1, s2, and two state variables v, rho. The dependency relationships among different variables are illustrated in the figure below:
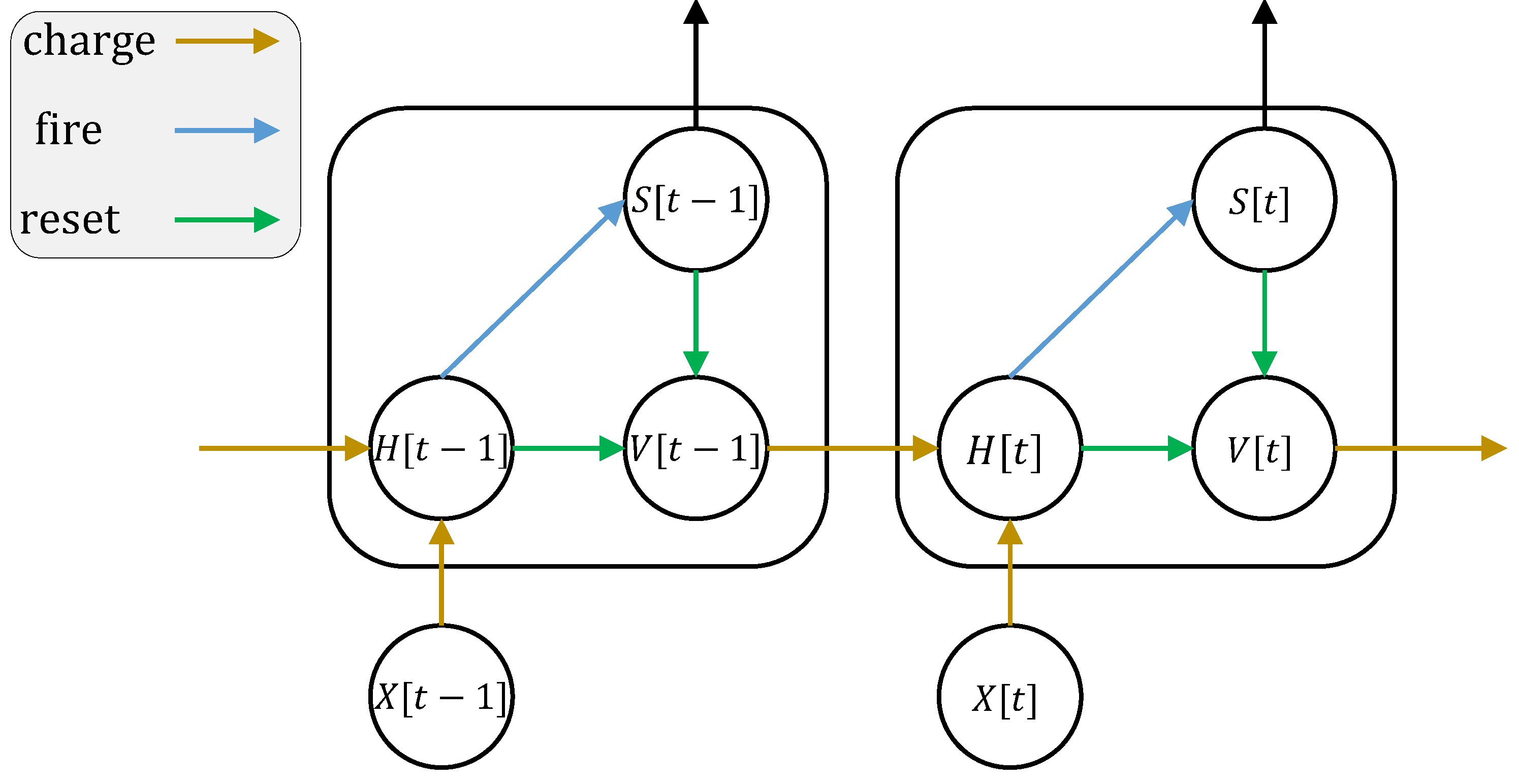
To generate a multi-step Triton kernel, use FlexSN:
from spikingjelly.activation_based import neuron
f = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="inductor",
store_state_seqs=True,
)
x = torch.randn([16, 3, 32, 32], device="cuda")
y = torch.randn([16, 3, 32, 32], device="cuda")
s1, s2 = f(x, y)
v, rho = f.state_seqs
print(s1.mean()) # tensor(0.0821, device='cuda:0', grad_fn=<MeanBackward0>)
print(s2.mean()) # tensor(0.1494, device='cuda:0', grad_fn=<MeanBackward0>)
print(v.mean()) # tensor(-0.2750, device='cuda:0', grad_fn=<MeanBackward0>)
print(rho.mean()) # tensor(0.4842, device='cuda:0', grad_fn=<MeanBackward0>)
The construction of FlexSN requires the following arguments:
core: a function that describes the single-step neuron dynamics, with the signature[*inputs, *states] -> [*outputs, *states].num_inputs, num_states, num_outputs: the numbers of inputs, state variables, and outputs, which should be consistent with the signature ofcore.example_inputs: example arguments forcore.FlexSNwill callcorewith these example inputs in order to capture the computation graph.example_outputs: optional, per-step output templates forcore. They are mainly used to determine output shapes and dtypes when the input sequence is empty (T == 0). On the"triton"/"inductor"path, if this argument is provided, each template tensor should match the firstexample_inputstensor's per-step shape and dtype.requires_grad: whether the arguments ofcorerequire gradients. The default value isNone, which means that all arguments require gradients (i.e., equivalent to allTrue).step_mode, backend: similar to other neuron modules, these two arguments determine the step mode and the backend. The"torch"backend is always available. The"triton","inductor", and"hop"backends are only valid whenstep_mode="m". In FlexSN,"triton"and"inductor"are equivalent labels for the same Triton path, while"hop"uses the HOP/eager-scan path.store_state_seqs: similar tostore_v_seqin other neuron modules, this argument determines whether state sequences are stored. IfTrue, the state sequences from the last run can be accessed via thestate_seqsattribute. This attribute is a list, where each element corresponds to the sequence of a specific state variable.
FlexSN also supports backward propagation, as shown in the following code block:
n_inductor = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="inductor",
store_state_seqs=True,
)
n_torch = neuron.FlexSN(
core=complicated_lif_core_generator(beta=0.5, gamma=0.9),
num_inputs=2,
num_states=2,
num_outputs=2,
example_inputs=(
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
torch.zeros([1], device="cuda"), torch.zeros([1], device="cuda"),
),
requires_grad=(True, True, True, True),
step_mode="m",
backend="torch",
store_state_seqs=True,
)
x = torch.randn([16, 3, 32, 32], device="cuda")
y = torch.randn([16, 3, 32, 32], device="cuda")
x_inductor = x.clone().requires_grad_(True)
y_inductor = y.clone().requires_grad_(True)
x_torch = x.clone().requires_grad_(True)
y_torch = y.clone().requires_grad_(True)
s1_inductor, s2_inductor = n_inductor(x_inductor, y_inductor)
s1_torch, s2_torch = n_torch(x_torch, y_torch)
grad = torch.randn_like(s1_inductor)
s1_inductor.backward(grad)
s1_torch.backward(grad)
v_inductor, rho_inductor = n_inductor.state_seqs
v_torch, rho_torch = n_torch.state_seqs
assert torch.allclose(s1_inductor, s1_torch)
assert torch.allclose(s2_inductor, s2_torch)
assert torch.allclose(x_inductor.grad, x_torch.grad, atol=1e-6, rtol=1e-6)
assert torch.allclose(y_inductor.grad, y_torch.grad, atol=1e-6, rtol=1e-6)
assert torch.allclose(v_inductor, v_torch, atol=1e-6, rtol=1e-6)
assert torch.allclose(rho_inductor, rho_torch)
print(s1_inductor.mean())
print(s2_inductor.mean())
print(x_inductor.grad.mean())
print(y_inductor.grad.mean())
print(v_inductor.mean())
print(rho_inductor.mean())
All assert statements pass, and the outputs are shown below. This demonstrates that the Triton scan kernels used by FlexSN are equivalent to the original PyTorch function in both forward and backward propagation.
tensor(0.0821, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.1494, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.0007, device='cuda:0')
tensor(6.2995e-05, device='cuda:0')
tensor(-0.2750, device='cuda:0', grad_fn=<MeanBackward0>)
tensor(0.4842, device='cuda:0', grad_fn=<MeanBackward0>)
With the workflow described above, users can obtain Triton-accelerated neuron models with very little code. Compared with the former auto_cuda module (see Implement CUPY Neuron), FlexSN is more flexible and general.
Note
In the example above, the state variables v and rho use the default zero initialization. Users can override the init_states() method to change the state initialization rule. The original definition of this method is shown below, where *args represents the arguments of forward():
class FlexSN(base.MemoryModule):
...
@staticmethod
def init_states(num_states: int, step_mode: str, *args) -> List[torch.Tensor]:
if step_mode == "s":
return [torch.zeros_like(args[0]) for _ in range(num_states)]
elif step_mode == "m":
return [torch.zeros_like(args[0][0]) for _ in range(num_states)]
else:
raise ValueError(f"Unsupported step mode: {step_mode}")
See FlexSN.init_states for details.
Note
FlexSN implements most features of SpikingJelly's neuron modules.
To call the generated kernels directly in a lightweight, transparent, and functional style, use FlexSNKernel.
Warning
When using FlexSN, please note the following:
The
"torch"backend can run on CPU or GPU. The"triton"and"inductor"backends require a GPU, and the"triton","inductor", and"hop"backends only support multi-step modestep_mode="m".The PyTorch backend is implemented by repeatedly calling
core.In the design of
FlexSN, compromises are made in efficiency in order to pursue generality. At present,IFNode,LIFNode, andPLIFNodeare equipped with highly optimized predefined Triton kernels. Please use these predefined kernels whenever possible to obtain higher performance.After completing a simulation with
FlexSN,reset()must be called to reset the neuron states.
Compatibility with torch.compile#
FlexSN exposes two equivalent backend labels for the same Triton path: backend="triton" and backend="inductor". The latter is the custom-op-wrapped entry to the same maintained Triton execution path. In practice, choose whichever label is clearer in your codebase; behavior and kernel generation are aligned.
Key properties:
Integrates with
torch.compile, enabling cross-layer fusion with surrounding modules.Ships dedicated Triton kernels for both inference and training.
Provides specialized final-state fast paths and HOP/eager fallbacks when dedicated kernels are unavailable.
Important
This section is about the Triton path. The
"triton"and"inductor"backends require CUDA.Ops inside
coremust be in theFX_TO_TRITONtable. Unsupported ops fall back toeager_scanwith a WARNING log. See Op Coverage below for the full list.For training,
coreshould use a surrogate gradient (e.g.Sigmoid) instead of a hard threshold; hard thresholds yield zero gradients by design.
Minimal Examples#
Inference:
import torch
import torch.nn as nn
from spikingjelly.activation_based.neuron.flexsn import FlexSN
def lif_core(x: torch.Tensor, v: torch.Tensor):
tau, v_th = 2.0, 1.0
h = v + (x - v) / tau
s = (h >= v_th).to(h.dtype)
return s, h * (1.0 - s)
neuron = FlexSN(core=lif_core, num_inputs=1, num_states=1,
num_outputs=1, step_mode="m", backend="inductor").cuda()
x = torch.randn(8, 64, 512, device="cuda")
with torch.no_grad():
out = neuron(x) # no torch.compile required
# Optional: wrap with torch.compile for cross-layer fusion
model = nn.Sequential(nn.Linear(512, 512), neuron, nn.Linear(512, 512)).cuda()
model = torch.compile(model, fullgraph=True)
out = model(x)
Training:
import torch
from spikingjelly.activation_based import surrogate
from spikingjelly.activation_based.neuron.flexsn import FlexSN
sg = surrogate.Sigmoid(alpha=4.0)
def lif_core_sg(x: torch.Tensor, v: torch.Tensor):
tau, v_th = 2.0, 1.0
h = v + (x - v) / tau
s = sg(h - v_th) # Sigmoid surrogate gradient
return s, h * (1.0 - s)
neuron = FlexSN(core=lif_core_sg, num_inputs=1, num_states=1,
num_outputs=1, step_mode="m", backend="inductor").cuda()
x = torch.randn(8, 64, 512, device="cuda", requires_grad=True)
out = neuron(x)
out.sum().backward() # BPTT via dedicated Triton fwd+bwd kernels
print(x.grad.shape) # [8, 64, 512]
torch.compile is optional in both examples. Without it, the "triton"
and "inductor" backends still use the same dedicated Triton scan kernels. With it,
FlexSN stays in the compiled graph through the custom-op path, which is the
mode to use when benchmarking cross-layer fusion with surrounding
Linear / Conv modules.
Supported Backends#
Backend |
Device |
Execution path |
Typical use / notes |
|---|---|---|---|
|
CPU / CUDA |
Pure PyTorch multi-step loop |
Reference implementation, debugging, CPU prototyping |
|
CUDA |
Same Triton path |
Primary high-performance path. |
|
CPU / CUDA |
HOP / eager scan path |
Experimentation, scan tracing, fallback path |
Runtime Behavior#
Under backend="triton" or backend="inductor":
Inference traces
corewithmake_fxand emits one Triton scan kernel withtl.static_range(T). Each inference call launches exactly one kernel, independent ofT.Training traces both forward and backward and emits dedicated Triton forward/backward scan kernels. Without
torch.compile, this is already the full Triton path.With
torch.compile, FlexSN still dispatches the same Triton kernels through opaque custom ops, while surrounding layers can be jointly compiled.If
coreuses unsupported ops, or if Triton kernels cannot be built, FlexSN falls back to the HOP/eager-scan path.
Practical recommendation:
Use the
"torch"backend for CPU work, debugging, or when you want simplest semantics.Use the
"triton"or"inductor"backend for actual high-performance GPU execution.Add
torch.compileonly when you want cross-layer fusion with surrounding modules.
Op Coverage#
The FX_TO_TRITON table currently covers the following ATen ops (supported for both inference and training):
Category |
Ops |
|---|---|
Arithmetic |
|
Transcendentals |
|
Rounding |
|
Activation / threshold |
|
Comparisons |
|
Logic / bitwise |
|
Binary math |
|
Clamp |
|
Type / construction |
|
Selection |
|
Backward-only |
|
Misc |
|
Ops not in this table (e.g. matrix ops, complex control flow) trigger eager_scan fallback with a WARNING log.