Triton Backend#
Author: Yifan Huang (AllenYolk)
中文版: Triton 后端
SpikingJelly version 0.0.0.1.0 introduces the Triton backend as an alternative to PyTorch and CuPy. Compared with the CuPy backend, the Triton backend offers better readability, extensibility, and maintainability, makes it easier to achieve higher GPU utilization, and has the potential to be applied to other hardware platforms.
This tutorial focuses on predefined neuron kernels with the Triton backend. For automatic kernel generation from custom dynamics functions, see FlexSN.
The following preparations and prerequisites are required:
Install Triton. It is recommended to use
triton >= 3.3.1.Be familiar with the SpikingJelly Neuron module.
Using Predefined Triton Kernels#
Forward and Backward Propagation#
The way to enable the Triton backend is similar to that of the CuPy backend. Taking LIFNode as an example:
import torch
from spikingjelly.activation_based import neuron
n = neuron.LIFNode(step_mode="m", backend="triton").to("cuda:0")
x = torch.randn([16, 1, 3, 32, 32], device="cuda:0") # [T, B, C, H, W]
s = n(x)
print(s.device, s.shape, s.mean())
# cuda:0 torch.Size([16, 1, 3, 32, 32]) tensor(0.0313, device='cuda:0')
Here, we construct an LIF neuron running in multi-step mode step_mode="m" and enable the Triton backend. After moving both the neuron and the input tensor to the "cuda:0" device, forward propagation can be performed. The Triton backend also supports backward propagation and produces (almost) identical results to other backends:
import torch
import torch.nn.functional as F
from spikingjelly.activation_based import neuron
n_triton = neuron.LIFNode(
step_mode="m", backend="triton", store_v_seq=True
).to("cuda:0")
n_torch = neuron.LIFNode(
step_mode="m", backend="torch", store_v_seq=True
).to("cuda:0")
x = torch.randn([16, 1, 3, 32, 32], device="cuda:0") # [T, B, C, H, W]
x_triton = x.clone().requires_grad_(True)
x_torch = x.clone().requires_grad_(True)
s_triton = n_triton(x_triton)
s_torch = n_torch(x_torch)
v_triton = n_triton.v_seq
v_torch = n_torch.v_seq
grad = torch.randn_like(s_triton)
s_triton.backward(grad)
s_torch.backward(grad)
assert torch.allclose(s_triton, s_torch)
print(s_triton.mean()) # tensor(0.0309, device='cuda:0', grad_fn=<MeanBackward0>)
assert torch.allclose(v_triton, v_torch)
print(v_triton.mean()) # tensor(-0.0702, device='cuda:0', grad_fn=<MeanBackward0>)
assert torch.allclose(x_triton.grad, x_torch.grad, rtol=1e-6, atol=1e-6)
print(
F.cosine_similarity(x_triton.grad.flatten(), x_torch.grad.flatten(), dim=0)
) # tensor(1., device='cuda:0')
Performance Benchmark#
The Triton backend supports torch.float16. Below, we use the performance benchmarking tools provided by Triton, namely triton.testing, to compare the efficiency of different backends:
import torch
import triton
from spikingjelly.activation_based import neuron, functional
DEVICE = "cuda:0"
def forward_backward(net, x_seq):
y_seq = net(x_seq)
y_seq.sum().backward()
x_seq.grad = None
functional.reset_net(net)
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=["T"],
x_vals=[4*i for i in range(1, 9)],
line_arg="backend",
line_vals=["torch", "cupy", "triton"],
line_names=["torch", "cupy", "triton"],
styles=[
('green', ':'), ('blue', '--'), ('red', '-.'),
],
ylabel='Execution Time (ms)',
plot_name='Performance-float16',
args={"N": 64, "C": 64*32*32, 'dtype': torch.float16},
)
)
def benchmark(T, N, C, dtype, backend):
net = neuron.LIFNode(
backend=backend,
step_mode='m',
).to(device=DEVICE, dtype=dtype)
x_seq = torch.rand(
[T, N, C], device=DEVICE, dtype=dtype, requires_grad=True
)
results = triton.testing.do_bench(
lambda: forward_backward(net, x_seq),
quantiles=[0.5, 0.2, 0.8],
grad_to_none=[x_seq]
)
return results
benchmark.run(save_path="./logs", print_data=True, show_plots=True)
When running on a single GeForce RTX 4090, the results are as follows:
Performance-float16:
T torch cupy triton
0 4.0 0.992784 0.667648 0.771072
1 8.0 3.459072 1.338368 0.857088
2 12.0 7.058432 1.988608 1.289216
3 16.0 11.737088 2.630736 1.704896
4 20.0 17.557505 3.263488 2.115584
5 24.0 24.517120 3.902464 2.533376
6 28.0 32.649216 4.535296 2.940928
7 32.0 41.872896 5.189120 3.365888
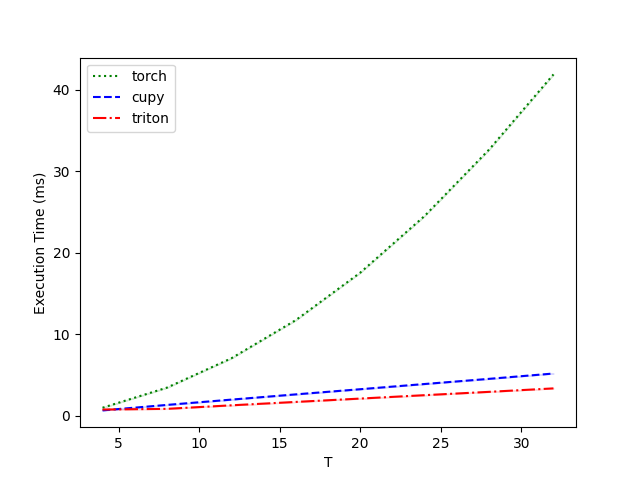
It can be observed that when both the data scale and sequence length T are large, the Triton backend exhibits a clear speed advantage over the CuPy and PyTorch backends.
Warning
When using predefined Triton neuron kernels, please note the following:
Currently, only the most commonly used
IFNode,LIFNode, andPLIFNodeare equipped with Triton kernels. More Triton kernels will be added in future updates.The Triton backend should be executed on a GPU.
The Triton backend only supports multi-step mode
step_mode="m".