强化学习DQN
本教程作者:fangwei123456,lucifer2859
本节教程使用SNN重新实现PyTorch官方的 REINFORCEMENT LEARNING (DQN) TUTORIAL。 请确保你已经阅读了原版教程和代码,因为本教程是对原教程的扩展。
更改输入
在ANN的实现中,直接使用CartPole的相邻两帧之差作为输入,然后使用CNN来提取特征。使用SNN实现,也可以用相同的方法,但目前的Gym若想 得到帧数据,必须启动图形界面,不便于在无图形界面的服务器上进行训练。为了降低难度,我们将输入更改为CartPole的Observation,即 Cart Position,Cart Velocity,Pole Angle和Pole Velocity At Tip,这是一个包含4个float元素的数组。训练的代码也需要做相应改动, 将在下文展示。
输入已经更改为4个float元素的数组,记下来我们来定义SNN。需要注意,在Deep Q Learning中,神经网络充当Q函数,而Q函数的输出应该是一 个连续值。这意味着我们的SNN最后一层不能输出脉冲,否则我们的Q函数永远都输出0和1,使用这样的Q函数,效果会非常差。让SNN输出连续值的 方法有很多,之前教程中的分类任务,网络最终的输出是输出层的脉冲发放频率,它是累计所有时刻的输出脉冲,再除以仿真时长得到的。在这个 任务中,如果我们也使用脉冲发放频率,效果可能会很差,因此脉冲发放频率并不是非常“连续”:仿真 \(T\) 步,可能的脉冲发放频率取 值只能是 \(0, \frac{1}{T}, \frac{2}{T}, ..., 1\)。
我们使用另一种常用的使SNN输出浮点值的方法:将神经元的阈值设置成无穷大,使其不发放脉冲,用神经元最后时刻的电压作为输出值。神经元实现这
种神经元非常简单,只需要继承已有神经元,重写 forward 函数即可。LIF神经元的电压不像IF神经元那样是简单的积分,因此我们使用LIF
神经元来改写:
class NonSpikingLIFNode(neuron.LIFNode):
def forward(self, dv: torch.Tensor):
self.neuronal_charge(dv)
# self.neuronal_fire()
# self.neuronal_reset()
return self.v
接下来,搭建我们的Deep Q Spiking Network,网络的结构非常简单,全连接-IF神经元-全连接-NonSpikingLIF神经元,全连接-IF神经元起到 编码器的作用,而全连接-NonSpikingLIF神经元则可以看作一个决策器:
class DQSN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, T=16):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(input_size, hidden_size),
neuron.IFNode(),
nn.Linear(hidden_size, output_size),
NonSpikingLIFNode(tau=2.0)
)
self.T = T
def forward(self, x):
for t in range(self.T):
self.fc(x)
return self.fc[-1].v
训练网络
训练部分的代码,与ANN版本几乎相同。需要注意的是,ANN使用两帧之差作为输入,而我们使用env返回的Observation作为输入。
ANN的原始代码为:
for i_episode in range(num_episodes):
# Initialize the environment and state
env.reset()
last_screen = get_screen()
current_screen = get_screen()
state = current_screen - last_screen
for t in count():
# Select and perform an action
action = select_action(state)
_, reward, done, _ = env.step(action.item())
reward = torch.tensor([reward], device=device)
# Observe new state
last_screen = current_screen
current_screen = get_screen()
if not done:
next_state = current_screen - last_screen
else:
next_state = None
# Store the transition in memory
memory.push(state, action, next_state, reward)
# Move to the next state
state = next_state
# Perform one step of the optimization (on the target network)
optimize_model()
if done:
episode_durations.append(t + 1)
plot_durations()
break
# Update the target network, copying all weights and biases in DQN
if i_episode % TARGET_UPDATE == 0:
target_net.load_state_dict(policy_net.state_dict())
SNN的训练代码如下,我们会保存训练过程中使得奖励最大的模型参数:
for i_episode in range(num_episodes):
# Initialize the environment and state
env.reset()
state = torch.zeros([1, n_states], dtype=torch.float, device=device)
total_reward = 0
for t in count():
action = select_action(state, steps_done)
steps_done += 1
next_state, reward, done, _ = env.step(action.item())
total_reward += reward
next_state = torch.from_numpy(next_state).float().to(device).unsqueeze(0)
reward = torch.tensor([reward], device=device)
if done:
next_state = None
memory.push(state, action, next_state, reward)
state = next_state
if done and total_reward > max_reward:
max_reward = total_reward
torch.save(policy_net.state_dict(), max_pt_path)
print(f'max_reward={max_reward}, save models')
optimize_model()
if done:
print(f'Episode: {i_episode}, Reward: {total_reward}')
writer.add_scalar('Spiking-DQN-state-' + env_name + '/Reward', total_reward, i_episode)
break
if i_episode % TARGET_UPDATE == 0:
target_net.load_state_dict(policy_net.state_dict())
另外一个需要注意的地方是,SNN是有状态的,因此每次前向传播后,不要忘了将网络 reset。涉及到的代码如下:
def select_action(state, steps_done):
...
if sample > eps_threshold:
with torch.no_grad():
ac = policy_net(state).max(1)[1].view(1, 1)
functional.reset_net(policy_net)
...
def optimize_model():
...
state_action_values = policy_net(state_batch).gather(1, action_batch)
next_state_values = torch.zeros(BATCH_SIZE, device=device)
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach()
functional.reset_net(target_net)
...
optimizer.step()
functional.reset_net(policy_net)
完整的代码可见于 clock_driven/examples/Spiking_DQN_state.py。可以从命令行直接启动训练:
>>> from spikingjelly.clock_driven.examples import Spiking_DQN_state
>>> Spiking_DQN_state.train(use_cuda=False, model_dir='./model/CartPole-v0', log_dir='./log', env_name='CartPole-v0', hidden_size=256, num_episodes=500, seed=1)
...
Episode: 509, Reward: 715
Episode: 510, Reward: 3051
Episode: 511, Reward: 571
complete
state_dict path is./ policy_net_256.pt
用训练好的网络玩CartPole
我们从服务器上下载训练过程中使奖励最大的模型 policy_net_256_max.pt,在有图形界面的本机上运行 play 函数,用训练了512次
的网络来玩CartPole:
>>> from spikingjelly.clock_driven.examples import Spiking_DQN_state
>>> Spiking_DQN_state.play(use_cuda=False, pt_path='./model/CartPole-v0/policy_net_256_max.pt', env_name='CartPole-v0', hidden_size=256, played_frames=300)
训练好的SNN会控制CartPole的左右移动,直到游戏结束或持续帧数超过 played_frames。play 函数中会画出SNN中IF神经元在仿真期间的脉
冲发放频率,以及输出层NonSpikingLIF神经元在最后时刻的电压:
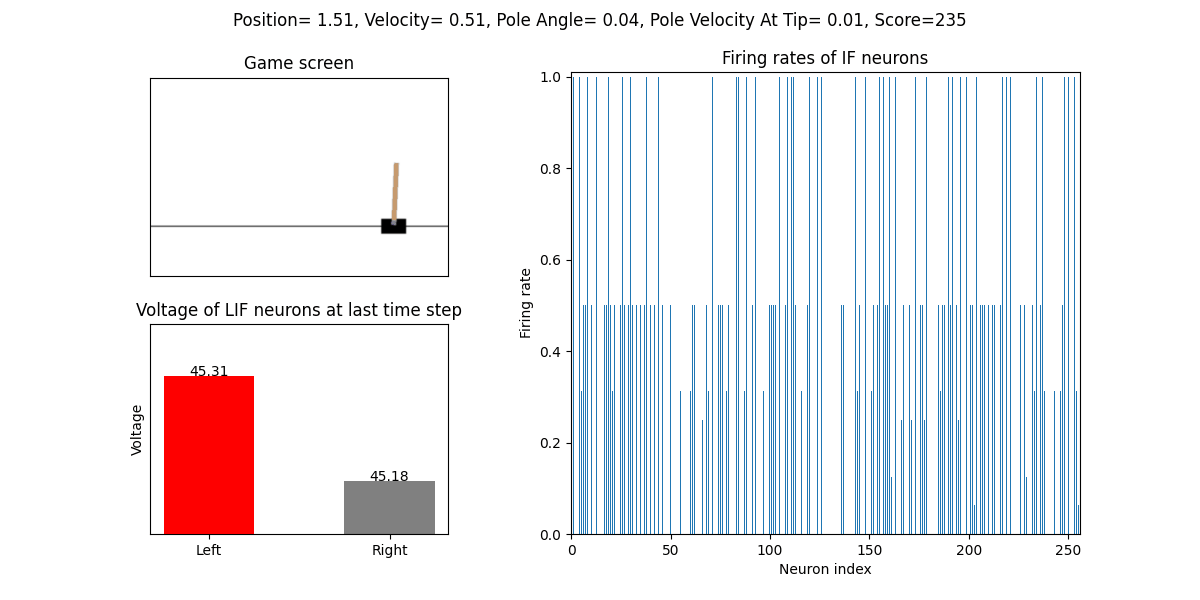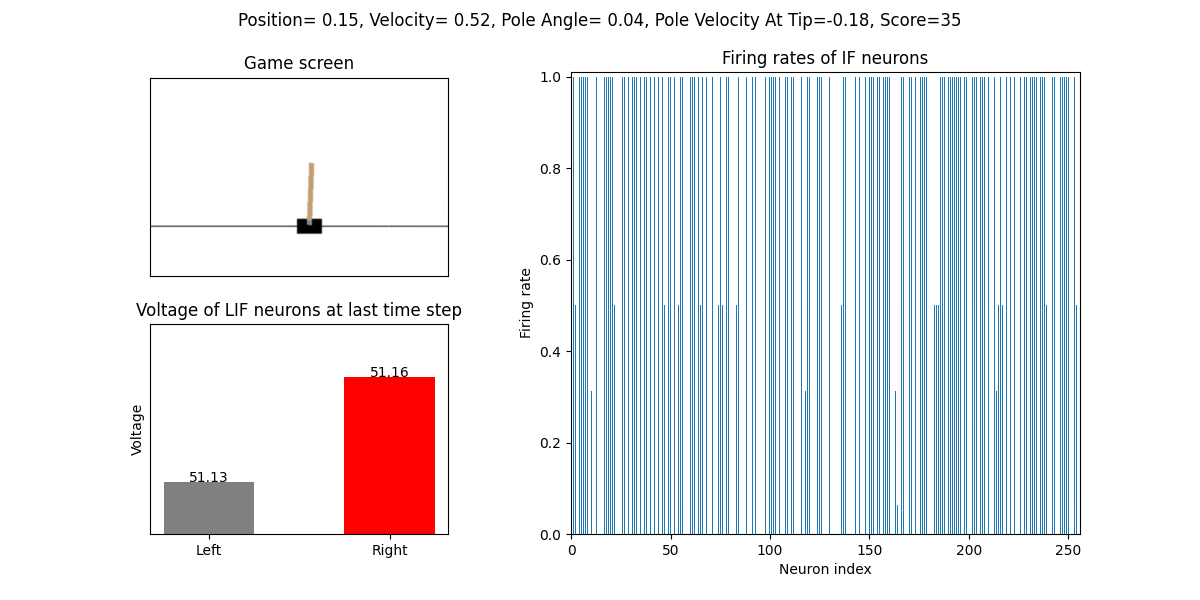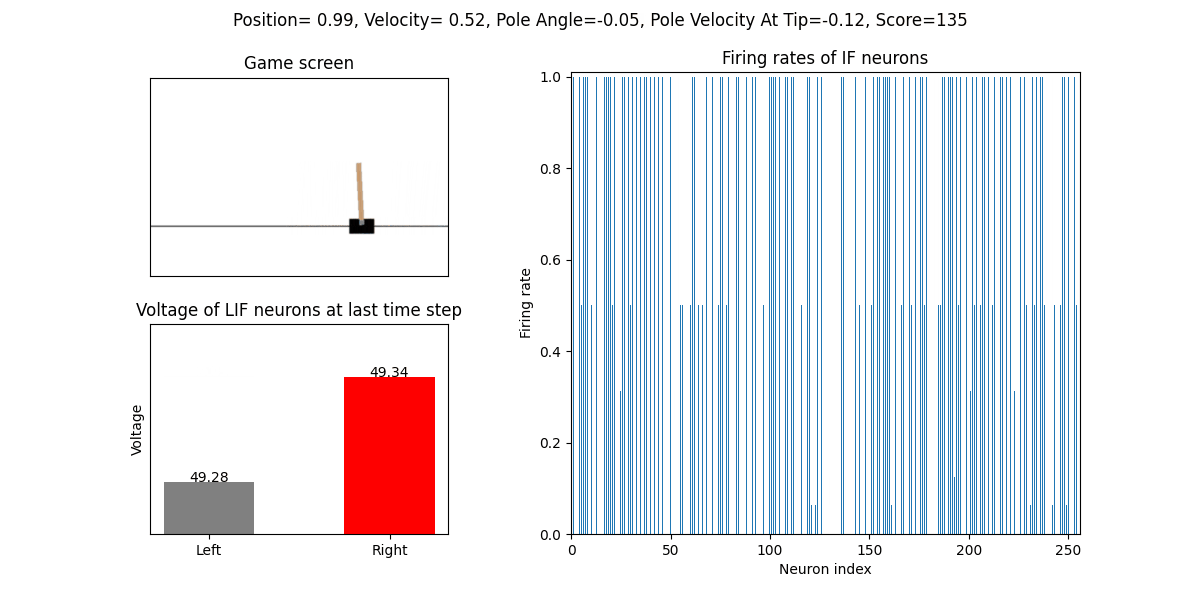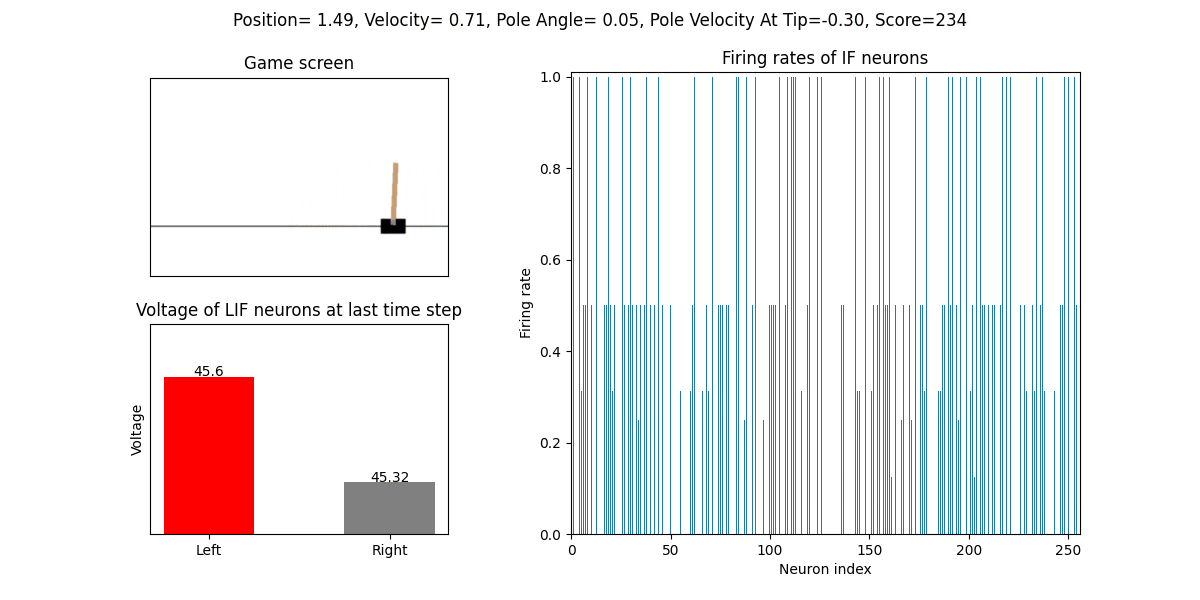
训练16次的效果:
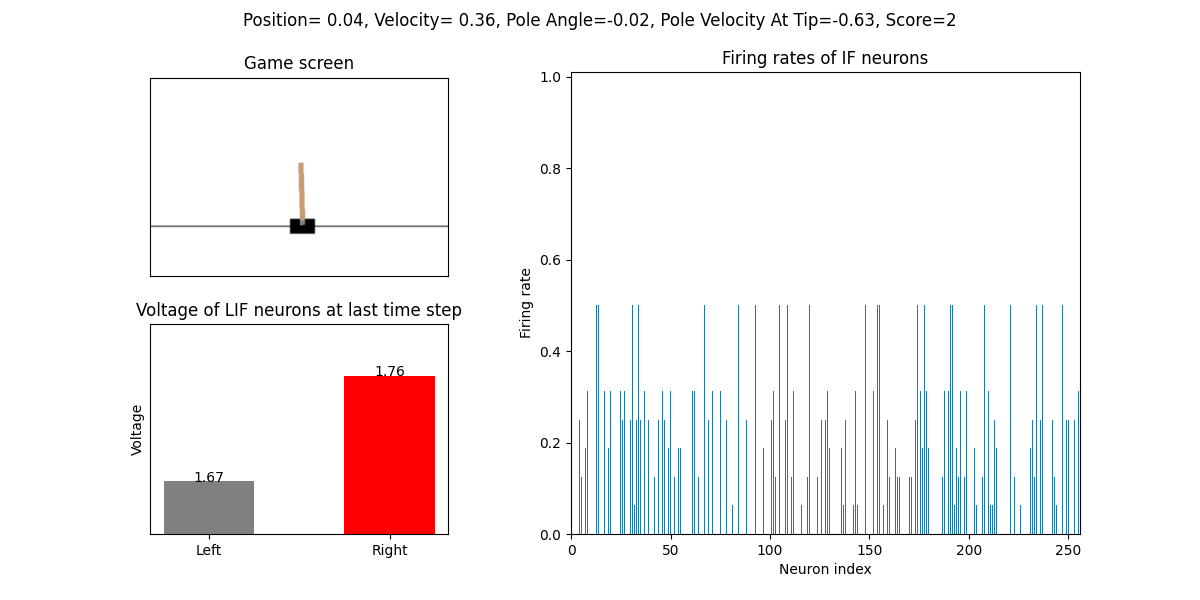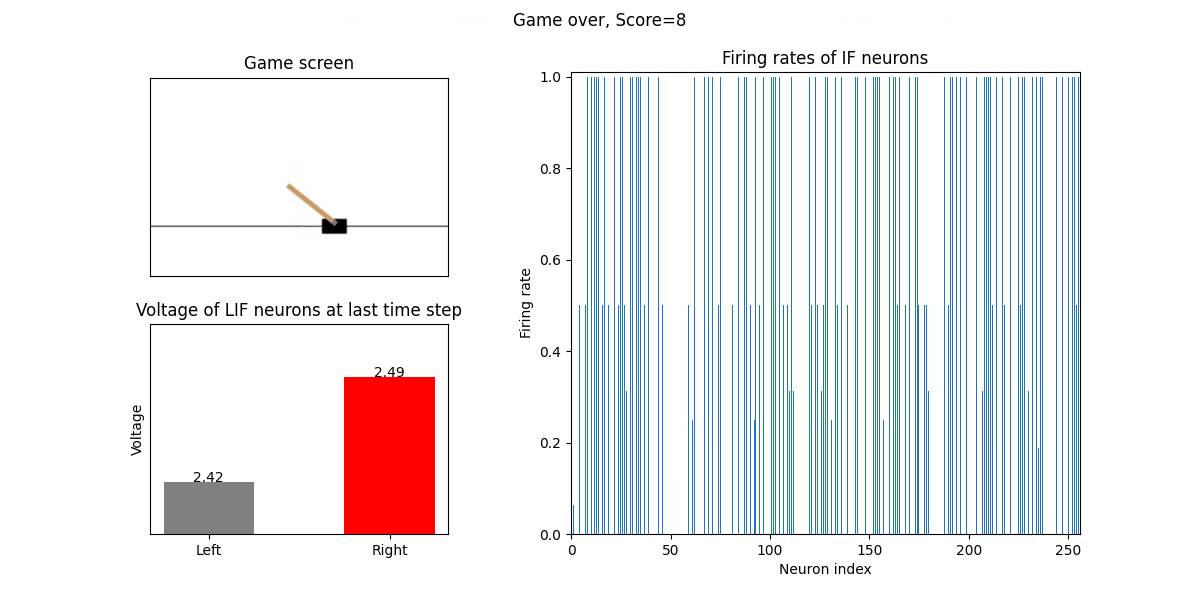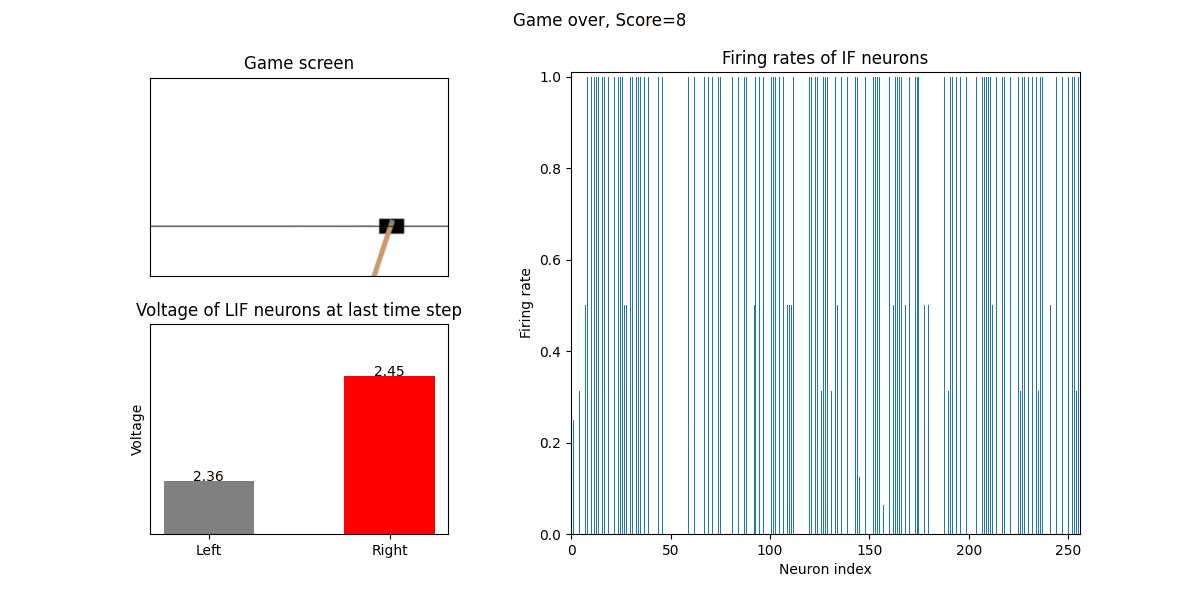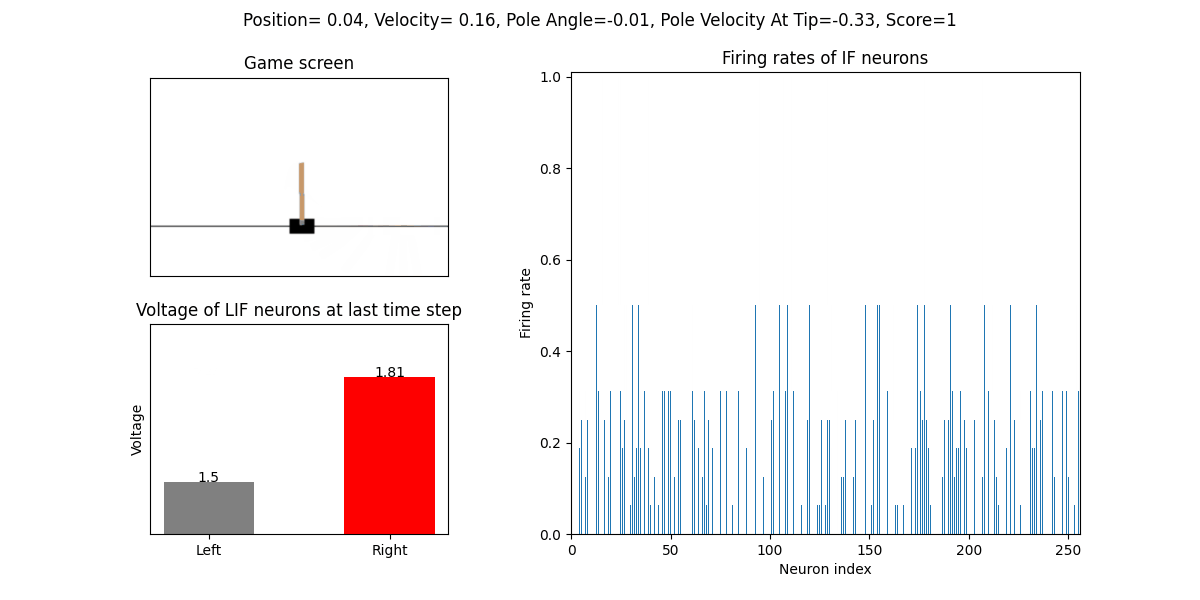
训练32次的效果:
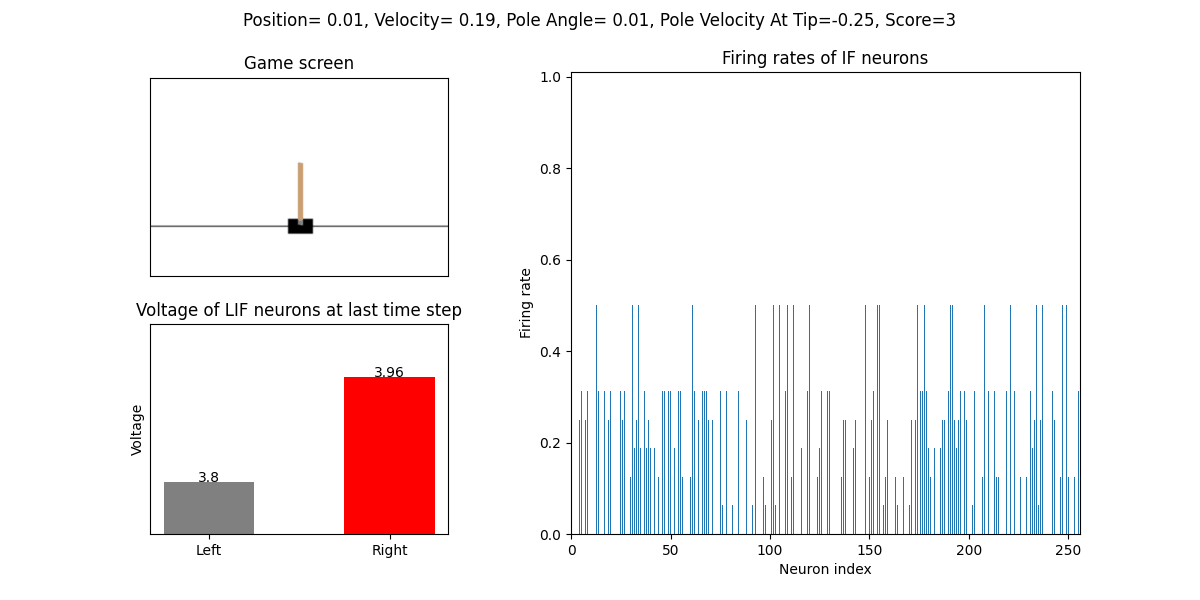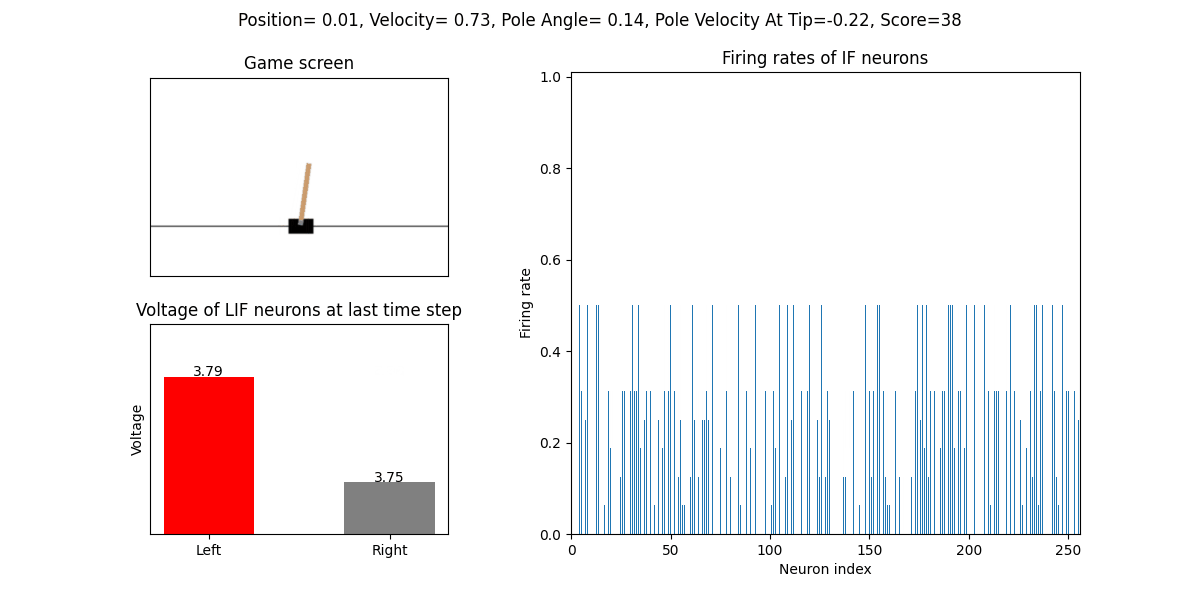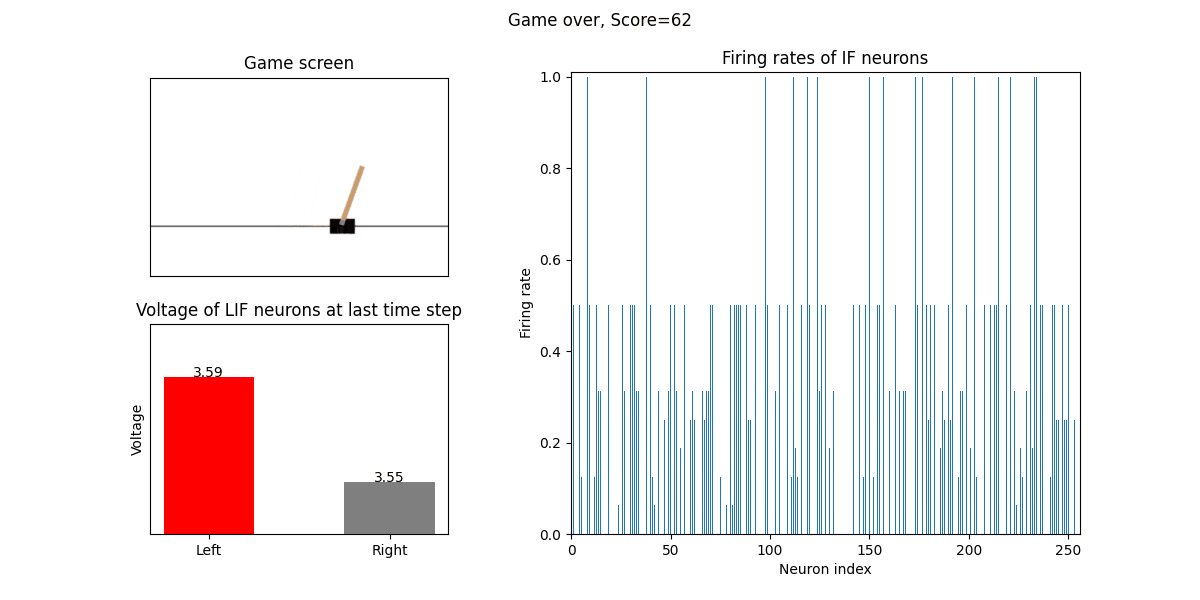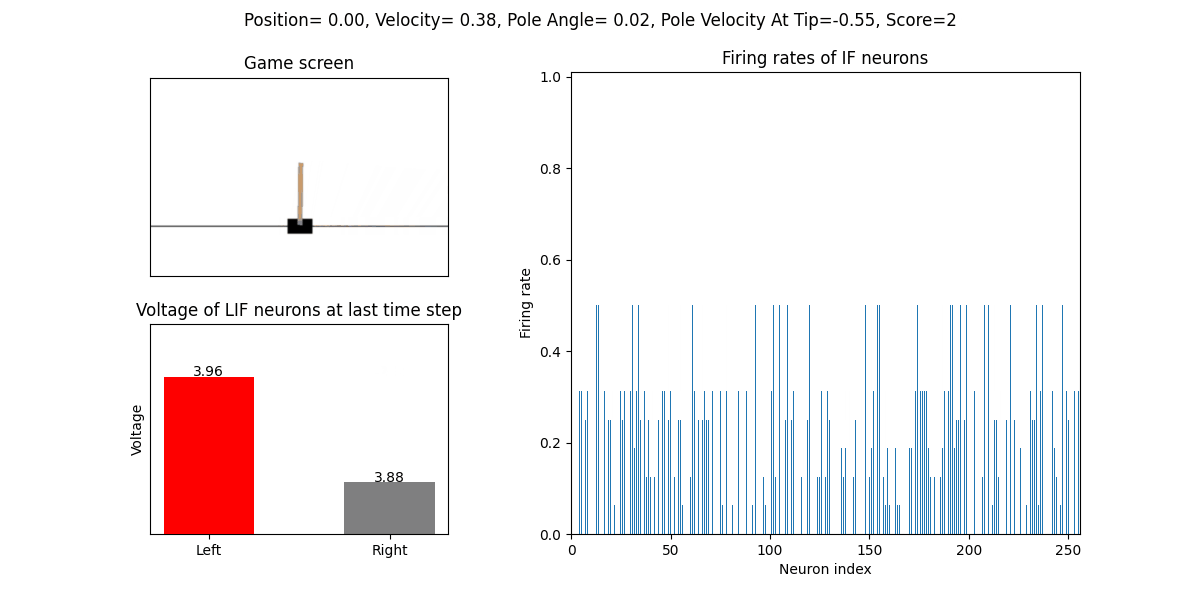
训练500个回合的性能曲线:

用相同处理方式的ANN训练500个回合的性能曲线(完整的代码可见于 clock_driven/examples/DQN_state.py):
