时间驱动
本教程作者: fangwei123456
本节教程主要关注 spikingjelly.clock_driven,介绍时钟驱动的仿真方法、梯度替代法的概念、可微分SNN神经元的使用方式。
梯度替代法是近年来兴起的一种新方法,关于这种方法的更多信息,可以参见如下综述:
Neftci E, Mostafa H, Zenke F, et al. Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-based optimization to spiking neural networks[J]. IEEE Signal Processing Magazine, 2019, 36(6): 51-63.
此文的下载地址可以在 arXiv 上找到。
SNN之于RNN
可以将SNN中的神经元看作是一种RNN,它的输入是电压增量(或者是电流与膜电阻的乘积,但为了方便,在 clock_driven.neuron 中用电压增量),隐藏状态是膜电压,输出是脉冲。这样的SNN神经元是具有马尔可夫性的:当前时刻的输出只与当前时刻的输入、神经元自身的状态有关。
可以用充电、放电、重置,这3个离散方程来描述任意的离散脉冲神经元:
其中 \(V(t)\) 是神经元的膜电压;\(X(t)\) 是外源输入,例如电压增量;\(H(t)\) 是神经元的隐藏状态,可以理解为神经元还没有发放脉冲前的瞬时;\(f(V(t-1), X(t))\) 是神经元的状态更新方程,不同的神经元,区别就在于更新方程不同。
例如对于LIF神经元,描述其阈下动态的微分方程,以及对应的差分方程为:
对应的充电方程为
放电方程中的 \(S(t)\) 是神经元发放的脉冲,\(g(x)=\Theta(x)\) 是阶跃函数,RNN中习惯称之为门控函数,我们在SNN中则称呼其为脉冲函数。脉冲函数的输出仅为0或1,可以表示脉冲的发放过程,定义为
重置表示电压重置过程:发放脉冲,则电压重置为 \(V_{reset}\);没有发放脉冲,则电压不变。
梯度替代法
RNN使用可微分的门控函数,例如tanh函数。而SNN的脉冲函数 \(g(x)=\Theta(x)\) 显然是不可微分的,这就导致了SNN虽然一定程度上与RNN非常相似,但不能用梯度下降、反向传播来训练。但我们可以用一个形状与 \(g(x)=\Theta(x)\) 非常相似,但可微分的门控函数\(\sigma(x)\) 去替换它。
这一方法的核心思想是:在前向传播时,使用 \(g(x)=\Theta(x)\),神经元的输出是离散的0和1,我们的网络仍然是SNN;而反向传播时,使用梯度替代函数的梯度 \(g'(x)=\sigma'(x)\) 来代替脉冲函数的梯度。最常见的梯度替代函数即为sigmoid函数 \(\sigma(\alpha x)=\frac{1}{1 + exp(-\alpha x)}\),\(\alpha\) 可以控制函数的平滑程度,越大的 \(\alpha\) 会越逼近 \(\Theta(x)\) 但越容易在靠近 \(x=0\) 时梯度爆炸,远离 \(x=0\) 时则容易梯度消失,导致网络也会越难以训练。下图显示了不同的 \(\alpha\) 时,梯度替代函数的形状,以及对应的重置方程的形状:
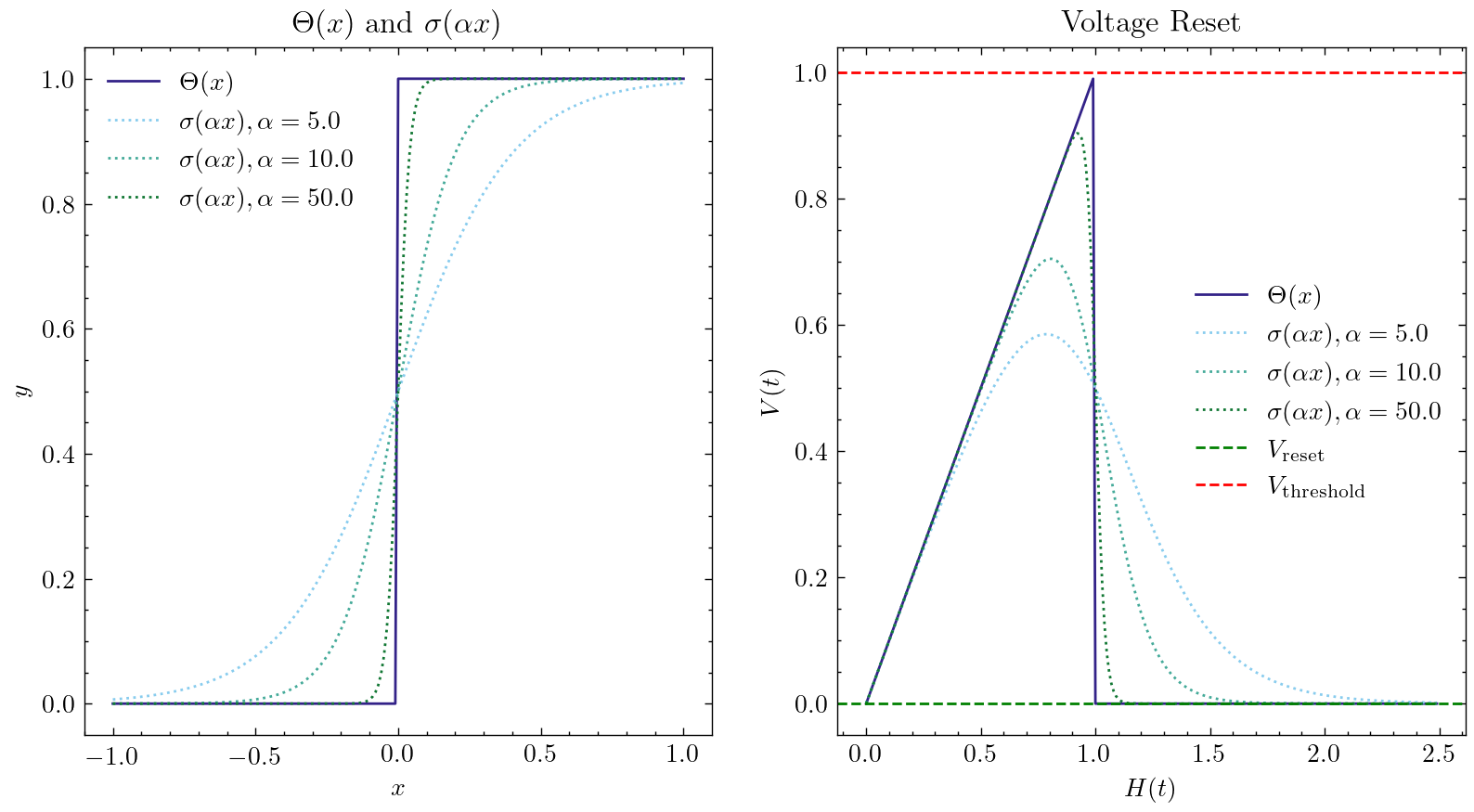
默认的梯度替代函数为 clock_driven.surrogate.Sigmoid(),在 clock_driven.surrogate 中还提供了其他的可选近似门控函数。
梯度替代函数是 clock_driven.neuron 中神经元构造函数的参数之一:
class BaseNode(base.MemoryModule):
def __init__(self, v_threshold: float = 1., v_reset: float = 0.,
surrogate_function: Callable = surrogate.Sigmoid(), detach_reset: bool = False):
"""
:param v_threshold: 神经元的阈值电压
:type v_threshold: float
:param v_reset: 神经元的重置电压。如果不为 ``None``,当神经元释放脉冲后,电压会被重置为 ``v_reset``;
如果设置为 ``None``,则电压会被减去 ``v_threshold``
:type v_reset: float
:param surrogate_function: 反向传播时用来计算脉冲函数梯度的替代函数
:type surrogate_function: Callable
:param detach_reset: 是否将reset过程的计算图分离
:type detach_reset: bool
可微分SNN神经元的基类神经元。
"""
如果想要自定义新的近似门控函数,可以参考 clock_driven.surrogate 中的代码实现。通常是定义 torch.autograd.Function,然后将其封装成一个 torch.nn.Module 的子类。
将脉冲神经元嵌入到深度网络
解决了脉冲神经元的微分问题后,我们的脉冲神经元可以像激活函数那样,嵌入到使用PyTorch搭建的任意网络中,使得网络成为一个SNN。在 clock_driven.neuron 中已经实现了一些经典神经元,可以很方便地搭建各种网络,例如一个简单的全连接网络:
net = nn.Sequential(
nn.Linear(100, 10, bias=False),
neuron.LIFNode(tau=100.0, v_threshold=1.0, v_reset=5.0)
)
示例:使用单层全连接网络进行MNIST分类
现在我们使用 clock_driven.neuron 中的LIF神经元,搭建一个单层全连接网络,对MNIST数据集进行分类。
首先确定所需超参数:
parser.add_argument('--device', default='cuda:0', help='运行的设备,例如“cpu”或“cuda:0”\n Device, e.g., "cpu" or "cuda:0"')
parser.add_argument('--dataset-dir', default='./', help='保存MNIST数据集的位置,例如“./”\n Root directory for saving MNIST dataset, e.g., "./"')
parser.add_argument('--log-dir', default='./', help='保存tensorboard日志文件的位置,例如“./”\n Root directory for saving tensorboard logs, e.g., "./"')
parser.add_argument('--model-output-dir', default='./', help='模型保存路径,例如“./”\n Model directory for saving, e.g., "./"')
parser.add_argument('-b', '--batch-size', default=64, type=int, help='Batch 大小,例如“64”\n Batch size, e.g., "64"')
parser.add_argument('-T', '--timesteps', default=100, type=int, dest='T', help='仿真时长,例如“100”\n Simulating timesteps, e.g., "100"')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float, metavar='LR', help='学习率,例如“1e-3”\n Learning rate, e.g., "1e-3": ', dest='lr')
parser.add_argument('--tau', default=2.0, type=float, help='LIF神经元的时间常数tau,例如“100.0”\n Membrane time constant, tau, for LIF neurons, e.g., "100.0"')
parser.add_argument('-N', '--epoch', default=100, type=int, help='训练epoch,例如“100”\n Training epoch, e.g., "100"')
初始化数据加载器:
# 初始化数据加载器
train_dataset = torchvision.datasets.MNIST(
root=dataset_dir,
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_dataset = torchvision.datasets.MNIST(
root=dataset_dir,
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
train_data_loader = data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True
)
test_data_loader = data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False
)
定义并初始化网络:
# 定义并初始化网络
net = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, 10, bias=False),
neuron.LIFNode(tau=tau)
)
net = net.to(device)
初始化优化器、编码器(我们使用泊松编码器,将MNIST图像编码成脉冲序列):
# 使用Adam优化器
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 使用泊松编码器
encoder = encoding.PoissonEncoder()
网络的训练很简单。将网络运行 T 个时间步长,对输出层10个神经元的输出脉冲进行累加,得到输出层脉冲释放次数 out_spikes_counter;使用脉冲释放次数除以仿真时长,得到输出层脉冲发放频率 out_spikes_counter_frequency = out_spikes_counter / T。我们希望当输入图像的实际类别是 i 时,输出层中第 i 个神经元有最大的激活程度,而其他神经元都保持沉默。因此损失函数自然定义为输出层脉冲发放频率 out_spikes_counter_frequency 与实际类别进行one hot编码后得到的 label_one_hot 的交叉熵,或MSE。我们使用MSE,因为实验发现MSE的效果更好一些。尤其需要注意的是,SNN是有状态,或者说有记忆的网络,因此在输入新数据前,一定要将网络的状态重置,这可以通过调用 clock_driven.functional.reset_net(net) 来实现。训练的代码如下:
print("Epoch {}:".format(epoch))
print("Training...")
train_correct_sum = 0
train_sum = 0
net.train()
for img, label in tqdm(train_data_loader):
img = img.to(device)
label = label.to(device)
label_one_hot = F.one_hot(label, 10).float()
optimizer.zero_grad()
# 运行T个时长,out_spikes_counter是shape=[batch_size, 10]的tensor
# 记录整个仿真时长内,输出层的10个神经元的脉冲发放次数
for t in range(T):
if t == 0:
out_spikes_counter = net(encoder(img).float())
else:
out_spikes_counter += net(encoder(img).float())
# out_spikes_counter / T 得到输出层10个神经元在仿真时长内的脉冲发放频率
out_spikes_counter_frequency = out_spikes_counter / T
# 损失函数为输出层神经元的脉冲发放频率,与真实类别的MSE
# 这样的损失函数会使,当类别i输入时,输出层中第i个神经元的脉冲发放频率趋近1,而其他神经元的脉冲发放频率趋近0
loss = F.mse_loss(out_spikes_counter_frequency, label_one_hot)
loss.backward()
optimizer.step()
# 优化一次参数后,需要重置网络的状态,因为SNN的神经元是有“记忆”的
functional.reset_net(net)
# 正确率的计算方法如下。认为输出层中脉冲发放频率最大的神经元的下标i是分类结果
train_correct_sum += (out_spikes_counter_frequency.max(1)[1] == label.to(device)).float().sum().item()
train_sum += label.numel()
train_batch_accuracy = (out_spikes_counter_frequency.max(1)[1] == label.to(device)).float().mean().item()
writer.add_scalar('train_batch_accuracy', train_batch_accuracy, train_times)
train_accs.append(train_batch_accuracy)
train_times += 1
train_accuracy = train_correct_sum / train_sum
测试的代码与训练代码相比更为简单:
print("Testing...")
net.eval()
with torch.no_grad():
# 每遍历一次全部数据集,就在测试集上测试一次
test_sum = 0
correct_sum = 0
for img, label in tqdm(test_data_loader):
img = img.to(device)
for t in range(T):
if t == 0:
out_spikes_counter = net(encoder(img).float())
else:
out_spikes_counter += net(encoder(img).float())
correct_sum += (out_spikes_counter.max(1)[1] == label.to(device)).float().sum().item()
test_sum += label.numel()
functional.reset_net(net)
test_accuracy = correct_sum / test_sum
writer.add_scalar('test_accuracy', test_accuracy, epoch)
test_accs.append(test_accuracy)
max_test_accuracy = max(max_test_accuracy, test_accuracy)
print("Epoch {}: train_acc={}, test_acc={}, max_test_acc={}, train_times={}".format(epoch, train_accuracy, test_accuracy, max_test_accuracy, train_times))
print()
完整的代码位于 clock_driven.examples.lif_fc_mnist.py,在代码中我们还使用了Tensorboard来保存训练日志。
可设置的(超)参数如下:
$ python <PATH>/lif_fc_mnist.py --help
usage: lif_fc_mnist.py [-h] [--device DEVICE] [--dataset-dir DATASET_DIR] [--log-dir LOG_DIR] [--model-output-dir MODEL_OUTPUT_DIR] [-b BATCH_SIZE] [-T T] [--lr LR] [--tau TAU] [-N EPOCH]
spikingjelly LIF MNIST Training
optional arguments:
-h, --help show this help message and exit
--device DEVICE 运行的设备,例如“cpu”或“cuda:0” Device, e.g., "cpu" or "cuda:0"
--dataset-dir DATASET_DIR
保存MNIST数据集的位置,例如“./” Root directory for saving MNIST dataset, e.g., "./"
--log-dir LOG_DIR 保存tensorboard日志文件的位置,例如“./” Root directory for saving tensorboard logs, e.g., "./"
--model-output-dir MODEL_OUTPUT_DIR
模型保存路径,例如“./” Model directory for saving, e.g., "./"
-b BATCH_SIZE, --batch-size BATCH_SIZE
Batch 大小,例如“64” Batch size, e.g., "64"
-T T, --timesteps T 仿真时长,例如“100” Simulating timesteps, e.g., "100"
--lr LR, --learning-rate LR
学习率,例如“1e-3” Learning rate, e.g., "1e-3":
--tau TAU LIF神经元的时间常数tau,例如“100.0” Membrane time constant, tau, for LIF neurons, e.g., "100.0"
-N EPOCH, --epoch EPOCH
训练epoch,例如“100” Training epoch, e.g., "100"
也可以直接在Python命令行运行它:
$ python
>>> import spikingjelly.clock_driven.examples.lif_fc_mnist as lif_fc_mnist
>>> lif_fc_mnist.main()
########## Configurations ##########
device=cuda:0
dataset_dir=./
log_dir=./
model_output_dir=./
batch_size=64
T=100
lr=0.001
tau=2.0
epoch=100
####################################
Epoch 0:
Training...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 937/937 [01:26<00:00, 10.89it/s]
Testing...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 157/157 [00:05<00:00, 28.79it/s]
Epoch 0: train_acc = 0.8641775613660619, test_acc=0.9071, max_test_acc=0.9071, train_times=937
保存和读取模型:
# 保存模型
torch.save(net, model_output_dir + "/lif_snn_mnist.ckpt")
# 读取模型
# net = torch.load(model_output_dir + "/lif_snn_mnist.ckpt")
需要注意的是,训练这样的SNN,所需显存数量与仿真时长 T 线性相关,更长的 T 相当于使用更小的仿真步长,训练更为“精细”,但训练效果不一定更好,因此 T 太大,SNN在时间上展开后就会变成一个非常深的网络,梯度的传递容易衰减或爆炸。由于我们使用了泊松编码器,因此需要较大的 T。
我们的这个模型,在Tesla K80上训练100个epoch,大约需要75分钟。训练时每个batch的正确率、测试集正确率的变化情况如下:
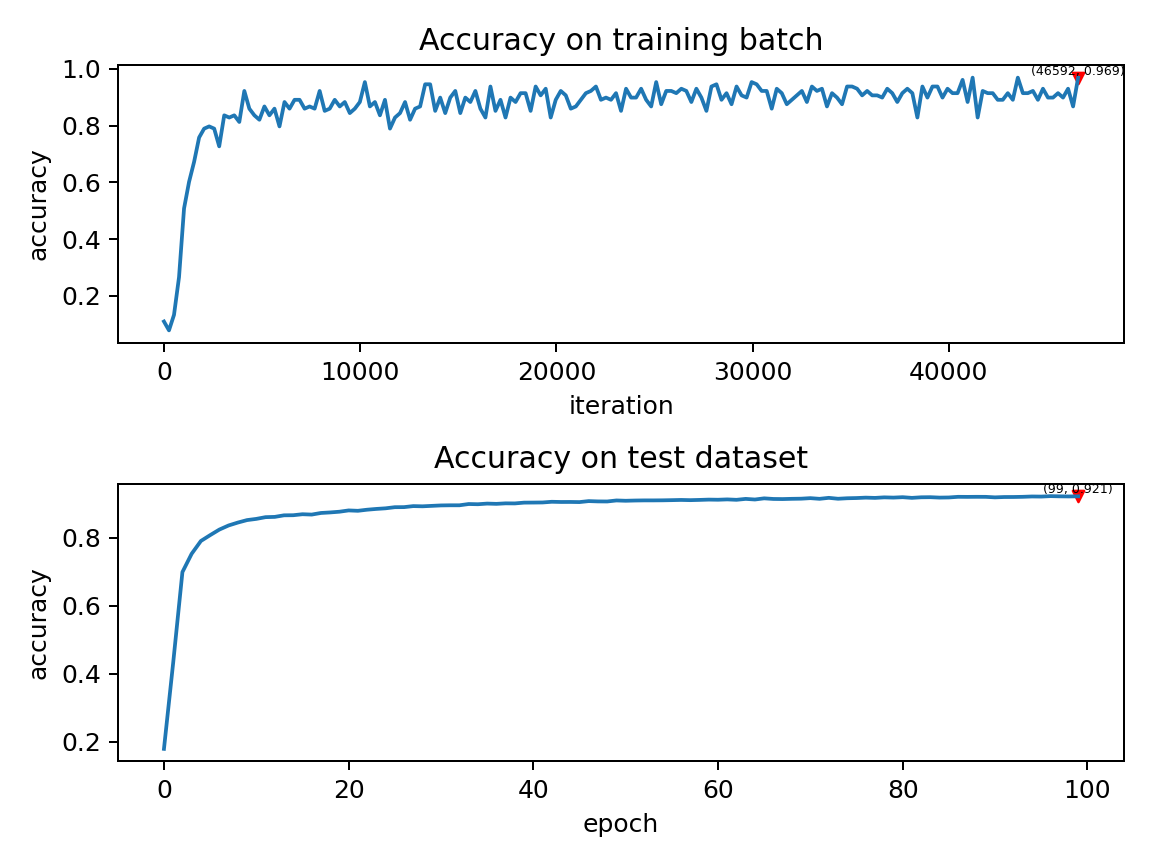
最终达到大约92%的测试集正确率,这并不是一个很高的正确率,因为我们使用了非常简单的网络结构,以及泊松编码器。我们完全可以去掉泊松编码器,将图像直接送入SNN,在这种情况下,首层LIF神经元可以被视为编码器。